From the application programmer's point of view, understanding
the CX API functionality is the most important thing. It contains two methods
and a few data structures that you must be familiar with, before proceeding
to writing your own applications.
Basic Idea
The basic idea is that in order to solve a problem, you break it into
a number of tasks with problem size smaller than the original one, and
then you combine their output in a meaningful way:
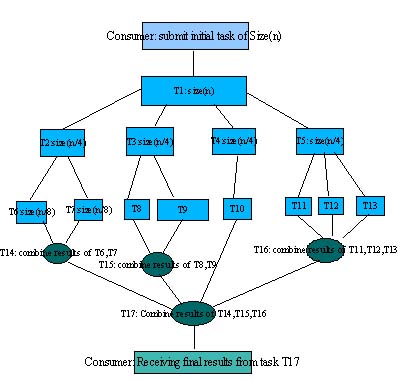
In the above figure, the consumer submits the initial task T1 that
corresponds to a problem of size(n), and then T1 creates four new
tasks of size(n/4), namely T2,T3,T4 and T5. When we have reach an adequate
problem size (here it took anly two levels from the root), we start the
reverse process which is to combine the results of the previous tasks.
How to split one tasks to others, and how to combine the results of other
tasks, is a problem specific process.
It is important to note that all the tasks, no matter what their functionality
is, they share some common things that are encaspulated in the TaskHeader
data structure (which is described later on). All tasks have some input
arguments, some attributes and some output arguments which normaly will
be used as input arguments by some other tasks, and so on. The following
table gives these values for task T14:
|
Input Arguments
|
Output Arguments
|
Properties
|
|
There are two input arguments, provided by tasks T6 and T7.
|
There is one output argument, that will be sent to task 17 as input
argument 1.
|
Among the properties are that this task can be computed only by a Producer
node, and it's marked as not ready during its creation. This
means it has to wait for some inpute arguments, before it is ready to get
executed. |
A brief description of the API methods and data structures can be found
here