Lecture 4: Namespaces, Structs, Padding
1 Namespaces
The purpose of a namespace is to avoid naming collisions.
A high-level scenario:
std::stringis a class in the standard library.- We've seen how we can specify the this by using
std::stringorusing namespace std. - But what if we are writing a sewing simulator and we want to write
our own class called
stringthat represents an actual string with a length. - The C++ compiler might be confused if we don't specify between our string implementation and the standard library's string implementation.
1.1 Example
// F1.h
#ifndef F1_H
#define F1_H
#include <iostream>
namespace CS32::F1 {
void someFunction() {
std::cout << "F1.someFunction()" << std::endl;
}
}
#endif
// F2.h
#ifndef F2_H
#define F2_H
#include <iostream>
namespace CS32::F2 {
void someFunction() {
std::cout << "F2.someFunction()" << std::endl;
}
}
#endif
#include "F1.h"
#include "F2.h"
int main() {
using namespace CS32::F1;
someFunction(); // F1.someFunction()
return 0;
}
# Makefile
CXX=clang++
CXXFLAGS=-std=c++17 -Wall
main.o: main.cpp F1.h F2.h
${CXX} ${CXXFLAGS} -c main.cpp -o main.o
main: main.o F1.h F2.h
${CXX} ${CXXFLAGS} -o main main.o
clean:
rm -f *.o main
using namespace CS32::F1printsF1.someFunction()using namespace CS32::F2printsF2.someFunction()using namespace CS32::F1; using namespace CS32::F2;causes a naming collision! The compiler cannot pick one implementation over the other.using CS32::F1::someFunctionprintsF1.someFunction()using CS32::F2::someFunctionprintsF2.someFunction()We can nest namespaces using
::. Writingnamespace CS32::F1 { // ... } // namespace CS32::F1Is the same as nesting namespace clauses like so:
namespace CS32 { namespace F1 { // ... } // namespace F1 } // namespace CS32
1.2 Global Namespace
- By default, all variables and functions are defined in a global namespace if no namespace is explicitly defined.
1.3 Appending to existing namespaces
- Namespace definitions can span multiple files (it adds on to the namespace if it already exists).
- Imagine if the standard library had to be defined in a single namespace block!!
1.4 Example - Namespaces spanning multiple files
// F1.h
#ifndef F1_H
#define F1_H
#include <iostream>
namespace CS32::F1 {
class string {
public:
void someFunction();
};
}
#endif
// F2.h
#ifndef F2_H
#define F2_H
#include <iostream>
namespace CS32::F2 {
class string {
public:
void someFunction();
};
}
#endif
// F1.cpp
#include <iostream>
#include "F1.h"
using namespace std;
namespace CS32::F1 {
void string::someFunction() {
cout << "F1.someFunction()" << endl;
}
}
// F2.cpp
#include <iostream>
#include "F2.h"
using namespace std;
namespace CS32::F2 {
void string::someFunction() {
cout << "F2.someFunction()" << endl;
}
}
// main.cpp
#include "F1.h"
#include "F2.h"
int main() {
CS32::F2::string x;
x.someFunction(); // prints “F2.someFunction()”
return 0;
}
# Makefile
CXX=clang++
CXXFLAGS=-std=c++17 -Wall
F1.o: F1.cpp F1.h
${CXX} ${CXXFLAGS} -c F1.cpp -o F1.o
F2.o: F2.cpp F2.h
${CXX} ${CXXFLAGS} -c F2.cpp -o F2.o
main.o: main.cpp F1.h F2.h
${CXX} ${CXXFLAGS} -c main.cpp -o main.o
main: main.o F1.h F2.h
${CXX} ${CXXFLAGS} -o main main.o
clean:
rm -f *.o main
1.5 Specifying something in the global namespace.
- It's possible that local definitions have namespace conflicts if using namespace … has a naming conflict.
- You can specify the global namespace by prepending "::" to indicate the global namespace.
1.6 Example
// main.cpp
using namespace CS32::F1;
void someFunction() {
cout << "in some function (global namespace)" << endl;
}
int main() {
// someFunction(); // which one?? – won’t compile.
::someFunction(); // knows it’s someFunction in global namespace
}
1.7 Anonymous namespace
We let the same namespace span multiple files above. There is a chance that we may pick the same name in two files defined in the same namespace. This is a likely problem in large C++ codebases. Luckily, there is a solution for when we want to hide implementation details:
// foo.cpp
// note that there is no name for this namespace. The functions
// defined inside are not available in other files
namespace {
int square(int x) {
return x * x;
}
}
1.8 Inline functions
In some cases, we may want to define (not just declare) a function in a header file. Common reasons for doing this include: enabling compiler optimizations (because the compiler sees the definition of the function, it may have more opportunities), or using features like templates where the compiler needs to see the template and all of its uses to generate specialized code.
In this case, we may define square in the .h file for some reason:
// F1.h
// ...
int square(int x) {
return x * x;
}
However, now there are two definitions of square in our program (one in
main.cpp another in F1.cpp because both of them include F1.h), and we
get a linker error:
% make
...
clang++ -std=c++17 -Wall -o main main.o F1.o F2.o
duplicate symbol 'square(int)' in:
main.o
F1.o
To fix this issue, we can tell the compiler to inline the definition of
square so that the definitions in other modules will be merged into one. If
we do this, then the linker will not see two disparate definitions for the
symbol square(int) but a merged single one. To do this, we mark square
with the keyword inline:
// F1.h
// ...
inline int square(int x) {
return x * x;
}
2 Structs
- Even in C, there was a way to represent complex data types called a
"Structure" or
struct - A struct brings together a set of heterogeneous members, similar to a class.
- Structs consist of zero or more members of various types.
- The sizeof an empty struct is 1 byte… Why?
- Because it ensures two different objects will have different addresses when dealing with pointer arithmetic
- This size gets optimized out when inheriting the struct (we will discuss it when discussing inheritance).
- Note: No difference between class / struct except struct defaults members to public and classes default to private.
- Once a struct is defined, you can declare variables, use them as return types, pass them in parameters, assign them to another struct of the same type… basically treat them like any type!
- The sizeof an empty struct is 1 byte… Why?
3 Memory Organization of Classes / Structs
- Strictly typed languages enable the compiler to allocate the appropriate memory for functions and types before runtime.
- In memory, the members are stored sequentially and space is allocated based on the types it contains.
- Therefore, the size of the struct seems like it should be the summation of sizes for all of its members… but not exactly.
- In C++, the members are stored in the declaration order only if all of them have the same visibility. So, if the class has a mix of public and private members, then the compiler can re-order members!
3.1 Memory Padding
- The concept of leaving blank space when allocating memory to a struct / class in order to improve access speeds when reading data. This arises from the design of the architecture, and how memory accesses work. What's said here is true for most modern architectures.
- Data is aligned by the types being stored (see figures below):
- char types (1 byte) - aligns with 1-byte boundaries
- short types (2 bytes) - aligns with 2-byte boundaries
- int types (4 bytes) - aligns with 4-byte boundaries
- double types (8 bytes) - aligns with 8-byte boundaries
- Time vs. space tradeoff
- Sacrificing a little bit of memory for faster access times.
- Depending on your application, simply ordering your members in the struct / class can save memory. May be important for applications running on hardware where memory is scarce.
3.2 Example
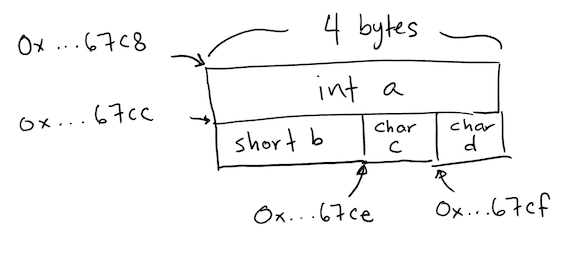
class X {
int a; // 4 bytes
short b; // 2
char c; // 1
char d; // 1
};
int main() {
X x;
cout << sizeof(x) << endl; // 8
cout << "&x = " << &x << endl; // 0x7ffee6a167c8
cout << "&x.a = " << &x.a << endl; // 0x7ffee6a167c8
cout << "&x.b = " << &x.b << endl; // 0x7ffee6a167cc
cout << "&x.c = " << reinterpret_cast<void*>(&x.c) << endl; // 0x7ffee6a167ce
cout << "&x.d = " << reinterpret_cast<void*>(&x.d) << endl; // 0x7ffee6a167cf
}
Class X:
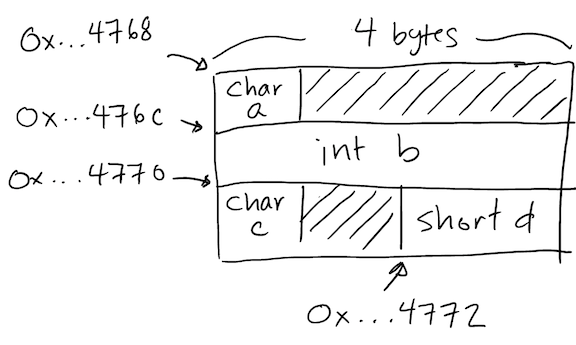
class Y {
char a; // 1 byte
int b; // 4
char c; // 1
short d; // 2
};
int main() {
Y y;
cout << sizeof(y) << endl; // 12
cout << "&y = " << &y << endl; // 0x7ffeed3d4768
cout << "&y.a = " << reinterpret_cast<void*>(&y.a) << endl; // 0x7ffeed3d4768
cout << "&y.b = " << &y.b << endl; // 0x7ffeed3d476c
cout << "&y.c = " << reinterpret_cast<void*>(&y.c) << endl; // 0x7ffeed3d4770
cout << "&y.d = " << &y.d << endl; // 0x7ffeed3d4772
}
Class Y:
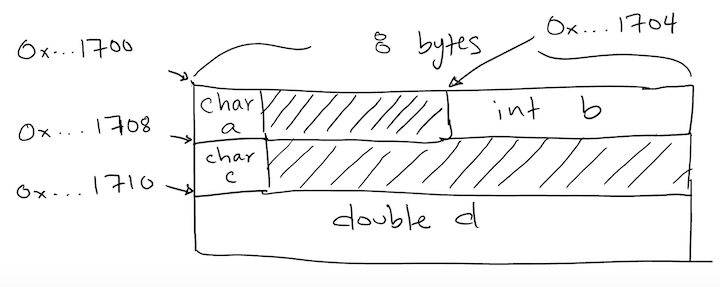
class Z {
public:
char a; // 1 byte
int b; // 4
char c; // 1
double d; // 8
};
int main() {
Z z;
cout << sizeof(z) << endl; // 24
cout << "&z = " << &z << endl; // 0x7ffee07c1700
cout << "&z.a = " << reinterpret_cast<void*>(&z.a) << endl; // 0x7ffee07c1700
cout << "&z.b = " << &z.b << endl; // 0x7ffee07c1704
cout << "&z.c = " << reinterpret_cast<void*>(&z.c) << endl; // 0x7ffee07c1708
cout << "&z.d = " << &z.d << endl; // 0x7ffee07c1710
}
Class Z:
- Note that the size of a class and how it's padded is determined by the largest member it contains. For example, a class containing one char will have a size of 1 byte (with no padding):
class A {
public:
char a; // 1 byte
};
int main() {
A a;
cout << sizeof(a) << endl; // 1 byte
}
- For additional reference, here's a good article that explains this well (in the alignment section): https://en.cppreference.com/w/cpp/language/object