#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include "int_add.h"
int
main(int argc, char *argv[])
{
int first_num = 10;
int second_num = 20;
printf("the sum of %d and %d is %d\n",
first_num,
second_num,
IntegerAdd(first_num,second_num));
return(0);
}
You probably already know where printf() comes from (Unix supplied it,
of course), but how it got into your program might be a bit of a mystery. In
this program, there is another function called IntegerAdd() which is
defined externally. In C, the idea is that your program can call lots of
externally defined functions, much like in Java or C++. The difference is
that they are linked in statically (for the most part) when you compile the
program. In this case, the code for IntegerAdd() (contained in
int_add.c) I've written
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int IntegerAdd(int a, int b)
{
return(a+b);
}
It is pretty simple, but how did it get into p1.c? Let's
look at the relevant lines of the makefile.
CC = gcc EXECUTABLES = p1 p2 p3 p4 CFLAGS = -g all: $(EXECUTABLES) clean: rm -f core *.o $(EXECUTABLES) a.out *.a int_add.o: int_add.c int_add.h $(CC) $(CFLAGS) -c int_add.c int_sub.o: int_sub.c int_sub.h $(CC) $(CFLAGS) -c int_sub.c libmylib.a: int_add.o int_sub.o ar cr libmylib.a int_add.o int_sub.o p1: p1.c int_add.o int_add.h $(CC) $(CFLAGS) -o p1 p1.c int_add.o p2: p2.c int_add.o int_add.h int_sub.o int_sub.h $(CC) $(CFLAGS) -o p2 p2.c int_add.o int_sub.o p3: p2.c libmylib.a $(CC) $(CFLAGS) -o p3 p2.c libmylib.a p4: p2.c libmylib.a $(CC) $(CFLAGS) -o p4 p2.c -L. -lmylibThe line that begins with int_add.o and the next line says the following
The lines that begin p1: mean the following
Now let's look at a slightly more complicated version in p2.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include "int_add.h"
#include "int_sub.h"
int
main(int argc, char *argv[])
{
int first_num = 10;
int second_num = 20;
printf("the sum of %d and %d is %d\n",
first_num,
second_num,
IntegerAdd(first_num,second_num));
printf("the difference between %d and %d is %d\n",
first_num,
second_num,
IntegerSub(first_num,second_num));
return(0);
}
Not hugely different, but you'll notice that there is a new external function
called IntegerSub() that is called in p2.c. The
makefile needs to specify, when p2.c is
compiled, that some of the external references may need to come from
int_add.o
and some may need to come from int_sub.o.
p2: p2.c int_add.o int_add.h int_sub.o int_sub.h
$(CC) $(CFLAGS) -o p2 p2.c int_add.o int_sub.o
The C compiler will first compile p2.c and then it will hunt
through all of the object files listed after it to try and resolve the
external references.
C was developed to write things like operating systems which may have many developers each doing a small piece, but who have to link their routines together to make a larger whole. As a result, the number of .o files you might need to specify on a single compile line could be very large. To help with this problem, Unix contains a way to build libraries consisting of one or more .o files. To create one of your own, you can use the ar command. Let's look, again, at the makefile.
libmylib.a: int_add.o int_sub.o
ar cr libmylib.a int_add.o int_sub.o
says to create a library called libmylib.a and to put in it all of the
code that is in int_add.o and int_sub.o. Now look at how the
binary for the program p3 is compiled from the source code for p2.c.
p3: p2.c libmylib.a
$(CC) $(CFLAGS) -o p3 p2.c libmylib.a
The programs p2 and p3 are identical. The only difference is
that when the C compiler built p3 it pulled the necessary external
references from libmylib.a. Notice, also the use of the -o flag
to create a new binary with a different name from the same source code for
p2.c.
One last thing. Much of the software you use from Unix in your programs (printf() for example) comes from libraries that are implicitly included by the C compiler automatically. These libraries come in two forms: statically linkable libraries and dynamically linkable libraries. The static versions have the suffic ".a" and the dynamically linkable ones have the suffix ".so).
For example, on CSIL, the C compiler automatically appends /usr/lib/libc.so.6 to the end of all compilations. If you want to see what is in libc.so.6 try typing the following command
objdump -T /usr/lib/libc.so.6The output is the list of relocatbale object files that were included when libc.so.6 was built.
Alternatively, for a statically linked library, the command is "ar -t." Try
ar -t libmylib.aon the library built by the make file and you should see
int_add.o int_sub.oas the contents of the library.
Unix observes a strange convention with respect to libraries and the "-l" flag to the C compiler. Much like for include files, there are a set of standard locations in which system libraries (like libc.a) are located. If you use the "-l" the system makes a library name that starts with "lib" and ends with ".a" or ".so". So "-lc" translates into "libc.a" or "libc.so". The linker which is a piece of software called by the compiler to link the object files together, takes this translated name and looks in places like "/usr/lib" for it.
Now it turns out that for some estoteric reason the file "/usr/lib/libc.s' is now a "linker script" on Fedora Linux (the Linux intalled in CSIL). You can look at it.
/* GNU ld script Use the shared library, but some functions are only in the static library, so try that secondarily. */ OUTPUT_FORMAT(elf32-i386) GROUP ( /lib/libc.so.6 /usr/lib/libc_nonshared.a AS_NEEDED ( /lib/ld-linux.so.2 ) )What this says (I think) is that the compiler finds "/usr/lib/libc.so" when it specifies "-lc" silently. It then finds this script and replaces the library with the commands that load /usr/lib/libc.so.6 and /usr/lib/libc_nonshared.a. This is a new wrinkle but it is essentially the same mechanism as we have been discussing.
You can change the places the C compiler will look with a "-L" option. Look at how the program p4 is compiled from the code for p2.c.
p4: p2.c libmylib.a
$(CC) $(CFLAGS) -o p4 p2.c -L. -lmylib
Here, the linker makes the library name libmylib.a from the "-lmylib"
option, and then looks in the standard places (where it doesn't find the
library) and in the places specified by the "-L" option (which is specified to
be the current working directory with a "."). Since it finds it there, it
uses the object code in the library to resolve the external references found
in p2.c.
The first thing to understand about any pointer is that it is a variable that contains a value that is, itself, the address of a memory location.
When C accesses a variable (any variable), it must fetch the value of that variable from a memory location and, if it is storing something back, it must use the memory address of the variable as the location where the value will be stored.
So the C code for
int a; a = a + 1;at the assembly language level generates something like
go to the memory address used to hold the variable 'a' and load the value into a register add 1 to that value in the register store the register contents in the memory at the address that is used for the variable 'a'In C, all variables have memory addresses because all variables can be changed when the program is running. So a pointer is a variable that can contain the memory address of another variable. It is more than that, but the first thing to understand is
For simple data types, this feature is easy to understand. For more complex data types, however, it can require some thinking.
First, it is important to understand the function of the * operators and the & operator. Roughly speaking
#include < stdlib.h >
#include < unistd.h >
#include < stdio.h >
int I_global = 25;
int main(int argc, char **argv)
{
int *pointer_to_int;
printf("address of I_global is %p\n",&I_global);
pointer_to_int = &I_global;
printf("contents of pointer_to_int are %p\n",pointer_to_int);
*pointer_to_int = *pointer_to_int + 10;
printf("the contents of I_global are %d\n",I_global);
return(0);
}
The variable pointer_to_int is a pointer variable. It can hold the
address of a variable that has type int. The & operator tells
the C compiler to generate the address of the variable immediately to its
right. So
pointer_to_int = &I_global;says that the pointer variable pointer_to_int gets the value that is the address of the integer variable I_global. When the program executes
*pointer_to_int = *pointer_to_int + 10;the compiler knows that the addition is an integer addition since both the first operand and the destination are *pointer_to_int and the type of *pointer_to_int is int. It prints out the value of I_global it should be 35. Why?
The first assignment loaded 25 into the integer I_global. Because the pointer variable pointer_to_int points to the memory occupied by I_global and the compiler knows that pointer_to_int can only point to integers, it knows to increment (using integer arithmetic) the integer value stored in that location by 10.
The compiler needs to know the type because the + operator is used both for integers and floating point numbers and the machine language code that the compiler must emit is different for each.
What can be confusing is that the following code is also legal (but perhaps immoral) C code
pointer_to_int = pointer_to_int + 10;In this example, without the * operator, the value contained in pointer_to_int is incremented and not the value in the memory pointed to by pointer_to_int. What is the value in pointer_to_int? It is the address of the variable I_global. On our machines that will be a large 64 bit number which prints as a hex number. For example, consider the code in pointer2.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
/*
* simple but pointless usages of pointers
* basic data types using different memory allocations
* demonstrates the compiler's use of type information for pointers
*/
int I_global;
int
main(int argc, char *argv[])
{
int i_stack;
int *i;
/*
* first pint the pointers at the global variables
*/
i = &I_global;
/*
* store a value in each global through the pointer
*/
*i = 17;
printf("i: %p, *i: %d, I_global: %d\n", i,*i,I_global);
/*
* now do some math
*/
i_stack = *i + 5;
printf("I_stack after integer add: %d\n",i_stack);
*i = 2.71828;
printf("I_global after fp store: %d\n",I_global);
*i = *i + 15;
printf("i: %p *i: %d after integer add of 15\n",i,*i);
i = &I_global;
i = i + 10;
printf("i: %p, I_global: %d after pointer add\n",i,I_global);
return(0);
}
When I run it on my laptop I get
./pointer2 i: 0x10cee3018, *i: 17, I_global: 17 I_stack after integer add: 22 I_global after fp store: 2 i: 0x10cee3018 *i: 17 after integer add of 15 i: 0x10cee3040, I_global: 17 after pointer addNotice that i and *i have different data types. That is i hold big 64 bit numbers that serve as memory addresses and *i is an integer. Thus, when the code executes
*i = *i + 5;you should expect *i to contain 22. What is the value of i after this statement? Exactly the same as it was before the statement. The addition does not affect the value of the variable i -- it affects the value of the memory to which i points. Notice that the pointer value of i remains 0x10cee3018.
However,
i = i + 10;increments the value in the pointer i. Thus,
i = &I_global;
i = i + 10;
printf("i: %p, I_global: %d after pointer add\n",i,I_global);
You should see the pointer value incremented by 0x0A and the value of
I_global unchanged.
But you don't.
Notice that
0x10cee3018+ 0x0A != 0x10cee3040In other words, when the code added 10 to the address in i which was 0x10cee3018 it didn't yield 0x10cee3022. Why?
Because the C compiler thinks that when you add an integer to a pointer variable as in
i = i + 10;you want to increment the pointer by the integer times the size of the data type the pointer points to. Thus, this C statement tells the compiler to increment the pointer by 10 * sizeof(int) since i points to an int. This feature, which looks strange, is there so that it is possible to step through an array of some data type by incrementing the pointer by an integer. For example
int I_array[255];
int *i;
i = &(I_array[0]);
*i = 10;
i = i + 1;
*i = 11;
printf("first element of I_array: %d\n",I_array[0]);
printf("second element of I_array: %d\n",I_array[1]);
Should assign 10 to the first element of I_array and 11
to the second element. To do that, the increment of i by 1 need
to move the pointer ahead by enough memory locations so that the store of
11 goes into the second element of the array.
Notice also that this code takes the address of the first element of the array using the & operator and loads that into the pointer variable i.
In general, my advice is do not use pointer arithmetic to access array values unless you are sure you need to do so. Thus, this code is better written as
int I_array[255];
I_array[0] = 10;
I_array[1] = 11;
printf("first element of I_array: %d\n",I_array[0]);
printf("second element of I_array: %d\n",I_array[1]);
If you are curious, it turns out that the compiler does kind of the same thing
with the I_array index as we did with pointer arithmetic. That is, it
computes the offset from the beginning of the array using the size of the
array's constituent data type multiplied by the index in the array. Thus,
the address of I_array[1] is the address of I_array[0] plus
sizeof(int). Thus everywhere the compiler sees I_array[x] it
computes (void *)(&(I_array[0]) + x*sizeof(int)) as the byte address of
the element indexed as x. If this last paragraph confuses you, ignore
it. It is only for informational purposes.
int I_array[10];allocates 10 * sizeof(int) bytes contiguously in memory. If an int is 4 bytes, then this memory region is 40 bytes in length. For our machines, it must also be aligned on a 4 byte boundary. To see the alignments, consider the code in pointer-array.c
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
/*
* print out some simple pointer values to see alignment
*/
char C_array[10];
int I_array[10];
double D_array[10];
int
main(int argc, char *argv[])
{
int *i_p;
char *c_p;
double *d_p;
c_p = &(C_array[0]);
printf("addr of first element in char array: %p\n",c_p);
c_p = &(C_array[1]);
printf("addr of second element in char array: %p\n",c_p);
i_p = &(I_array[0]);
printf("addr of first element in int array: %p\n",i_p);
i_p = &(I_array[1]);
printf("addr of second element in int array: %p\n",i_p);
d_p = &(D_array[0]);
printf("addr of first element in double array: %p\n",d_p);
d_p = &(D_array[1]);
printf("addr of second element in double array: %p\n",d_p);
return(0);
}
When I run this code I get
./pointer-array addr of first element in char array: 0x10986a020 addr of second element in char array: 0x10986a021 addr of first element in int array: 0x10986a080 addr of second element in int array: 0x10986a084 addr of first element in double array: 0x10986a030 addr of second element in double array: 0x10986a038Notice that the first character in the char array is aligned on an 8-byte boundary but the second is not. The C compiler will try and align variables when it thinks there is no harm in doing so. Thus, if you ask it to create a global char array (as in this code) it will align the first byte on an 8-byte boundary. However, it can't do that for the second bye and have the memory remain contiguous. Notice that the addresses align on 4-byte boundaries for int and 8-byte for double.
When allocating arrays from the heap using malloc(), however, you need to keep track of their size explicitly in the code. Notice that in the previous example we defined the array to contain exactly 10 elements in each case. What is we wanted to create the array based on the size of the user's input? We could define the largest array the user could ever want but that might be wasteful if the user wants a small array.
The way to you this in C is to understand that the array is really defined by three things
int *I_array; I_array = (int *)malloc(10 * sizeof(int));and then treat I_array almost exactly in the same way you'd have treated it if you had allocated it statically as we did in the previous example. The one difference is illustrated by this piece of code
int I_array[10];
int *J_array;
J_array = (int *)malloc(10 * sizeof(int));
printf("size of I_array: %d\n",sizeof(I_array));
printf("size of J_array: %d\n",sizeof(J_array));
will print two different values even though I_array ad J_array are
otherwise equivalent. Can you guess what the output is? Turns out that
the sizeof() operator reports the byte size that the compiler
sees in the code. Thus, sizeof(I_array) is 40 but
sizeof(J_array) is 8 since on a 64-bit x86 (like the ones we
use) all pointer values require 8 bytes of storage.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int
main(int argc, char *argv[])
{
int A;
int *B;
int **C;
A = 10;
B = &A;
C = &B;
printf("&A: %p, &B: %p, &C: %p\n",&A,&B,&C);
printf("A: %d, B: %p, C: %p\n",A,B,C);
printf("A: %d, B: %p, *C: %p\n",A,B,*C);
printf("A: %d, *B: %d, **C: %d\n",A,*B,**C);
return(0);
}
should prove instructional. I get
&A: 0x7ffd6635aa9c, &B: 0x7ffd6635aa90, &C: 0x7ffd6635aa88 A: 10, B: 0x7ffd6635aa9c, C: 0x7ffd6635aa90 A: 10, B: 0x7ffd6635aa9c, *C: 0x7ffd6635aa9c A: 10, *B: 10, **C: 10A is an integer that contains the value 10. B is a pointer to integer that contains the address of A. C is a pointer to a pointer to an integer that contains the address of B. Thus using the * operator on B gives the value in the memory pointer to by B which is the memory used to store A and that value is 10. Dereferencing C with the * operator gives the value in the memory C points to which the memory used to hold the value in B which is the address of A. Dereferencing that again gets you to the value store in A.
Also note that A is 4-byte aligned, but B and C are 8-byte aligned. Also, the address of A is bigger than the address of B and the address of C. That isn't an accident. We'll discuss this relationship more below when we discuss stacks.
Where this comes into play with respect to pointers is when a function wants to pass back a value through a parameter. C functions can only return a single value. If you want to write a function that returns more than one value you have to either
For example, imagine that I want to write a function that returns two integers and a double. I could use the following code
struct return_value
{
int i1;
int i2;
double d1;
};
struct return_value *MyFunction()
{
struct return_value *r;
r = (struct return_value *)malloc(sizeof(struct return_value));
r->i1 = 10;
r->i2 = 12;
r->d1 = 3.1415;
return(r);
}
where the fields i1, i2, and d1 are the two integers and the double.
Notice that in this example, I have to use malloc() to allocate the
memory for
return value structure. The caller would need to free this memory when it was
done with the three values -- every caller. If you forget one there is a
memory leak.
It turns out that some compilers (but not all) will let you get away with the following trick:
struct return_value MyFunction()
{
struct return_value r;
r.i1 = 10;
r.i2 = 12;
r.d1 = 3.3415;
return(r);
}
These two examples are good example of why people hate C. Unless you really
understand what the compiler is doing, it doesn't make sense that these both
are legal.
In the second example, the return type for the function is not a pointer to a struct return_value but an actual struct return_value. So is the local variable r. Because the compiler can "see" the sizes of all of the data types in the structure, it will allocate the space on the stack for r. Similarly, when r is returned, the compiler copies it whole hog from the stack to the memory of the caller.
Again, not all compilers still allow structures to be passed as arguments or return values because you can make them huge. What if you did the following
struct bad_return
{
int i;
int j;
int I_array[10000000];
};
struct bad_return MyFunction()
{
struct bad_return r;
r.i = 10;
r.j = 12;
return(r);
}
Notice that the compiler will need to make a structure on the stack that is
40M (because the I_array field is 40M) and then copy it all to the caller even
when the function doesn't touch the array.
In general, then, you should avoid passing structures as arguments and or return values. Instead, you should use the first example where you pass a pointer to a structure since the pointer is only 8 bytes no matter how big the structure is.
However, returning to the example where MyFunction() wants to return two integers and a double, all of the code needed to malloc/free the structure as well as the structure definition itself can be a little tedious. Instead, what you can do is to have the function return nothing as its return values and, instead, fill in memory locations set out by the caller to hold the values. For example,
void MyFunction(int *i1, int *i2, double *d1)
{
*i1 = 10;
*i2 = 12;
*d1 = 3.1415;
return;
}
Here, the void type says that there is no return value. The function
uses its parameters as pointers to the data types it produces and the *
operator to store the values in those memory locations. These are called
out parameters since they let the function push value out of its scope.
You could also elect to return one of the values, but have the other two as out parameters:
int MyFunction(int *i2, double *d1)
{
*i2 = 12;
*d1 = 3.1415;
return(10);
}
In this example, the first integer is just returned and the type of the
function is int.
Pthreads uses this style in pthread_create(). The return value is an integer indicating whether the call has succeeded or not and the first argument is an out parameter for a thread identifier having type pthread_t.
Notice that if you want to pass a pointer back as an out parameter, you wind up with a pointer to a pointer. For example consider the program in-out.c
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
void NewFunction(int *i1, int **p1)
{
int *j;
*i1 = 10;
j = (int *)malloc(sizeof(int));
*j = 12;
*p1 = j;
return;
}
int main(int argc, char **argv)
{
int I;
int *J;
NewFunction(&I,&J);
printf("I: %d, J: %p, *J: %d\n",I,J,*J);
free(J);
return(0);
}
It works this way. The function NewFunction() has two out parameters: one
for an integer and another for a pointer to an integer. The caller passes the
address of an integer &I and the address of a pointer to an integer
&J as the arguments. The function mallocs the memory and passes a
pointer to that memory through the second out parameter which main must then
free.
Here is the output:
./in-out I: 10, J: 0x15522a0, *J: 12
Various Linux library functions understand this convention. For example, the function printf() will use this convention with the %s type specifier to print out strings.
char *S = "My dog is happy!";
printf("%s\n",S);
works as you might expect. However, the compiler is hiding the definition of
a string from you in this example in a way that is designed to make you think
strings are actually a C data type. This code is equivalent in function to
char *S;
S = (char *)malloc(17);
S[0] = 'M';
S[1] = 'y';
S[2] = ' ';
S[3] = 'd';
S[4] = 'o';
S[5] = 'g';
S[6] = ' ';
S[7] = 'i';
S[8] = 's';
S[9] = ' ';
S[10] = 'h';
S[11] = 'a';
S[12] = 'p';
S[13] = 'p';
S[14] = 'y';
S[15] = '!';
S[16] = 0;
printf("%s\n",S);
free(S);
Notice that the code has to allocate an additional element for the zero at the
end. A common mistake is to forget this extra value. Another common mistake
is to assume that malloc() zeros it out for you. It doesn't and
printf() is looking for a zero to know where the string ends.
Again, if the compiler can "see" the entire string at compile time, it will allow you to define a string contant. Modern compilers (but not older ones) enforce the immutability of this constant.
However, often the strings are not known at compile time. To make string processing easier, Linux includes a set of function calls for manipulating strings. To see a list run
man stringThere are many and you are free to use them at will. Just remember that they all assume
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
int main(int argc, char **argv)
{
int i;
for(i=0; i < argc; i++) {
printf("arg %d: is %s with length %ld\n",
i,
argv[i],
strlen(argv[i]));
}
return(0);
}
Try running it as in
./string1 arg 0: is ./string1 with length 9This execution tells you a few things. First, the first argument of any C program on Linux is the name of the program itself. The variable argc must have been 1 and the index of the first argument in argv is 0.
Next, notice that argv is really an array of pointers to characters. It is equivalent to write char *argv[] in C. I don't feel like one way is better than another but you may have a prference.
Thus argc tells you how many entries there are in the argv array and each entry in the argv array is a pointer to a character. C and Linux define each pointer in the argv array to point, in fact, to a string: an array of characters that has the last character element set to zero. Thus argv[0] is a pointer to a "null terminated" array of characters -- a string.
How long is this string? The strlen() function says that it is 9 elements long. If you count of the characters that get printed in the string -- "./string1" -- you'll see that it is 9. Notice, though, that the trailing 0 that must be there, isn't counted. For example, in string2.c the code
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
int main(int argc, char **argv)
{
int i;
char *p;
int j;
for(i=0; i < argc; i++) {
printf("arg %d: ",i);
p = argv[i];
j = 0;
while(p[j] != 0) {
printf("%c",p[j]);
j++;
}
printf(" len: %ld, j: %d\n", strlen(argv[i]),j);
}
return(0);
}
Here you can see that the while loop only terminates when the element in the
array of
characters holding the string (pointed to by p in the code)
conatins a zero.
In the following execution
./string2 arg 0: ./string2 len: 9, j: 9Notice that the value of j indicates that this occurs in the 10th element of argv[0]. Since we count from zero, elements 0 through 8 -- that is 9 elements -- contain characters that are not zero. The 10th value (element indexed by 9) is zero causing the loop to exit.
Try this code with a few other arguments just for fun:
./string2 my dog is happy! arg 0: ./string2 len: 9, j: 9 arg 1: my len: 2, j: 2 arg 2: dog len: 3, j: 3 arg 3: is len: 2, j: 2 arg 4: happy! len: 6, j: 6or perhaps
./string2 I hate C 1 2 3 45 arg 0: ./string2 len: 9, j: 9 arg 1: I len: 1, j: 1 arg 2: hate len: 4, j: 4 arg 3: C len: 1, j: 1 arg 4: 1 len: 1, j: 1 arg 5: 2 len: 1, j: 1 arg 6: 3 len: 1, j: 1 arg 7: 45 len: 2, j: 2Here you should notice that the argument parsing for a C program under Linux uses spaces to separate arguments (the last argument prints as 45 rather tha two separate arguments). There are clever ways to tell the shell to change this behavior but in this class you should assume that each argument to a program is separated by white space on the command line.
There is also a function for copying a string. Here (for reasons that the example will illustrate) you will want to use the version that takes a maximum length to copy: strncpy(char *dest, char *src, int len)
This function takes the pointer to the place where the copy will be made as its first arguments, a pointer to the place where data top be copied is as its second argument, and the number of bytes to copy as its third argument.
Take a long look at the code in string3.c as it illustrates a few subtleties.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
/*
* do some argument parsing with strncmp() and strncpy()
*/
int main(int argc, char **argv)
{
int i;
int next;
char *p;
char *a;
char arg1[4096];
int found = 0;
int len;
for(i=1; i < argc; i++) {
p = argv[i];
if(strncmp(p,"arg1:",strlen("arg1:")) == 0) {
next = i + 1;
if(next >= argc) {
printf("arg1 value missing\n");
exit(1);
}
a = argv[next];
strncpy(arg1,a,sizeof(arg1));
len = strlen(a);
if(len >= sizeof(arg1)) {
len = sizeof(arg1) - 1;
}
arg1[len] = 0;
found = 1;
}
}
if(found == 1) {
printf("arg1 found with value %s\n",
arg1);
} else {
printf("no arg1 value found\n");
}
return(0);
}
First off, what does the program do? It looks through the argument list passed
to it for the string "arg1:" and then extracts into an array on the stack the
next string. Thus, if your program's api was
./string3 arg1: first-argumentit parses the argument list looking for the value immediately following the keyword "arg1:".
Run it a few times:
./string3 no arg1 value found ./string3 arg1: arg1 value missing ./string3 arg1: dog! arg1 found with value dog! ./string3 arg1: happy dog! arg1 found with value happy ./string3 arg1: happy-dog! arg1 found with value happy-dog! ./string3 arg1 dog! no arg1 value found ./string3 Arg1: dog! no arg1 value foundHopefully there are no surprises here. White space separates the arguments so only the string immediately after "arg1:" is considered. The full string is compared so the ":" matters. Notice that the comparison is case sensitive. There is a version of strncmp() that does a case smash first. See the main pages for details.
The code is worth analyzing for a couple of reaosns. First, notice thatt he destination for the copy is on the stack.
char arg1[4096];
.
.
.
strncpy(arg1,a,sizeof(arg1));
The call to strncpy() copies the string from the src array pointed to
by a into the arg1 array. Notice, though, that if this code
used
strcpy(arg1,a);instead, you could pass an arbitrarily long string and it would keep copying -- even past the end of the arg1 array. In this case, I've made arg1 4K bytes in size but you can vreate a string longer than that. In this case, if you are clever you can construct a string that puts the x86 return code in just the right place so that when the fucntion returns it jumps to your code. This is called a "buffer overflow attack."
The way to safeguard against it is to make sure that you never copy more from a string than the destination can hold. Here, we use the sizeof() operator. However you still need to be careful. Consider the following alternative version.
int main(int argc, char **argv)
{
int i;
int next;
char *p;
char *a;
char *arg1;
int found = 0;
int len;
arg1 = (char *)malloc(4096);
for(i=1; i < argc; i++) {
p = argv[i];
if(strncmp(p,"arg1:",strlen("arg1:")) == 0) {
next = i + 1;
if(next >= argc) {
printf("arg1 value missing\n");
exit(1);
}
a = argv[next];
strncpy(arg1,a,sizeof(arg1));
len = strlen(a);
if(len >= sizeof(arg1)) {
len = sizeof(arg1) - 1;
}
arg1[len] = 0;
found = 1;
}
}
if(found == 1) {
printf("arg1 found with value %s\n",
arg1);
} else {
printf("no arg1 value found\n");
}
free(arg1);
return(0);
}
This code is actually safe but has a bug. Can you spot it? The call to
sizeof(arg1) will return 8 because I've changed the type to be
a pointer to character and called malloc() instead. To make it correct
you would need to change the third argument in strncpy() to be 4096 as
well.
Notice also that you need to take the minimum of the string length and the size of the target buffer when punching the zero in at the end. Also, the zero needs to go in the last element which is indexed by an integer that is one less than the size of the array.
To keep from having to keep track of that last location in the code (which is both error prone and adds code clutter), what you can do is to zero out the buffer before the copy and then punch a 0 into the very end just to be safe. The routine memset() provided with the string libraries is handy for this purpose but you can also do it "by hand." For example, in string4.c:
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
int main(int argc, char **argv)
{
int i;
int next;
char *p;
char *a;
char arg1[4096];
int found = 0;
int len;
/*
* zero out the buffer by hand
*/
for(i=0; i < sizeof(arg1); i++) {
arg1[i] = 0;
}
for(i=1; i < argc; i++) {
p = argv[i];
if(strncmp(p,"arg1:",strlen("arg1:")) == 0) {
next = i + 1;
if(next >= argc) {
printf("arg1 value missing\n");
exit(1);
}
a = argv[next];
strncpy(arg1,a,sizeof(arg1));
/*
* punch zero in at the end just to be sure
*/
len = sizeof(arg1) - 1;
arg1[len] = 0;
found = 1;
}
}
if(found == 1) {
printf("arg1 found with value %s\n",
arg1);
} else {
printf("no arg1 value found\n");
}
return(0);
}
That's about all of the string processing you need, but by all means read up
on the other functions that are available and use them if you like. The key
things to remember are
The first thing to grasp is that, as mentioned, C understands the sizes of data types and whether they need to be aligned, but you control how the memory is allocated. What is less obvious is that there are
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int A;
int foo()
{
int A;
A = 15;
return(A);
}
int bar()
{
int A;
A = 20;
return(A);
}
int main(int argc, char **argv)
{
int foo_val;
int bar_val;
A = 7;
printf("A: %d\n",A);
foo_val = foo();
printf("A: %d, foo_val: %d\n",A,foo_val);
bar_val = bar();
printf("A: %d, bar_val: %d\n",A,bar_val);
return(0);
}
the variable A appears in three places: in foo(), in
bar(), and as a global
variable. The scoping rules say that a variable declaration is fenced by its
scope. Thus, the name A in foo() is only good within the
brackets that define foo's function body. A global variable is one that is
not defined within any function body (including main's).
In this example, the scopes overlap. The global A is valid as long as there is not a more local A in the scope where it is accessed. That is, in foo() and in bar() the local A takes precedence, but in main() where there is no local A the global A is used. Thus the rule is that the innermost scope takes precedence.
Here is the output which, hopefully, makes sense to you.
A: 7 A: 7, foo_val: 15 A: 7, bar_val: 20
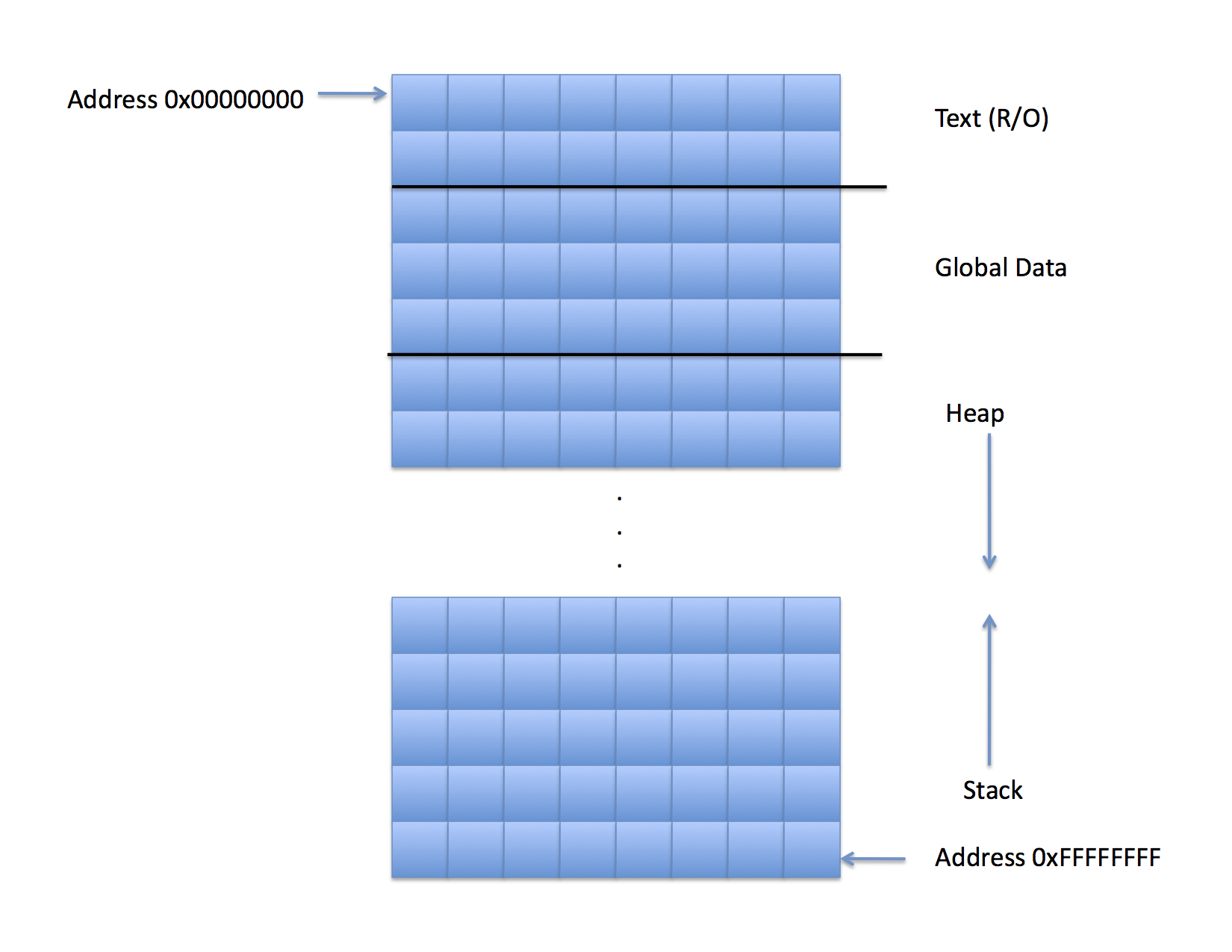
The first memory location in any process you will encounter has address 0x00000000 In this example I've depicted a 32 bit address space so the last memory location has address 0xFFFFFFFF. For the C compilers you will encounter each memory location that has an address is a byte. Thus the second square from the left on the first line has memory address 0x00000001 and it can hold an 8-bit byte and one to the right of it has memory address 0x00000002, and so on. In my figures, I will draw memory spaces in this way, with the low address at the top of the figure and the high address at the bottom (I don't know why I think of it this way but I do). I'll also assume that addresses go up when moving left to right across a line (line reading a page of text in the western world). Thus, the first byte of the second line of squares in the figure has memory address 0x00000008. I'll also use hex notation and 8 digits when referring to an address to differentiate it from the contents of a non pointer variable.
This process format is called the a.out format and (with a few small exceptions) it is pretty much how all Linux processes are layed out in memory.
The first segment (in the lowest set of contiguous addresses) is called the text segment and it is read-only memory. All of the code in a program (but none of the variables) are stored in the text segment. The hardware prevents the CPU from modifying any bytes in the text segment once the proicess begins executing so it is not possible for a Linux program to modify its own code "on the fly." That's considered a feature that prevents nasty bugs from arising.
Thus all variables (which can change their values) must be in one of the other three segments depicted: Global data, heap, or stack.
Global variables defined at compile time are located in the Global data segment. In the mem1.c example, the global A is located in the Global data segment. Since the compiler knows the type of A it tells the code generator to set aside enough space in the Global data segment for an integer and it remembers the address of that space as the address of global A and uses it whenever global A needs to be accessed.
Local variables that are defined in a function are put in the Stack segment. However, they are not allocated at compile time (as are the variables in the Global data segment). Instead, the compiler generates code to allocate space on the stack when a function body is entered (i.e. the function is called) and also to remove that space when the function calls return(). To give as much space as possible for local variables, the stack is located at the opposite end of the memory space from the Text and Global data segments. They grow toward higher addresses while the stack grows toward lower addresses. Thus as more and more global variables are added to a program the Global data segment gets bigger by adding memory locations at successively higher addreses. As local variables get bigger (or call depth increases -- see below) the stack gets bigger by taking up memory at successively smaller address locations. If they meet in the middle, the process is out of memory.
The reason the compiler uses the stack for local variables is because C was invented before threads were available. In an unthreaded C program, there can only be one function active at a time. The CPU includes a special register called a stack pointer that points to the "top" of the stack at any momemnt. When a function gets called, the C compiler inserts in the code an instruction to decrement the stack pointer by enough space to hold all of the local variables. The code within the fucntion addresses these variables relative to the stack pointer register. When the function calls return() the return code compiled into the function increments the stack pointer by enough addresses to "remove" all of the space that was allocated when the function was called.
Thus, logically, local variables are allocated on the stack each time the function is called and deallocated each time the function returns.
The only other segment to understand is the Heap segment. Like the stack, the heap is used to allocate memory dynamically. Unlike the stack, however, the compiler does not automatically insert code to do so. Instead, the heap is available for you to use as the programmer using the malloc() and free() functions. When you call malloc() memory locations are set aside in the heap for you to use and the address of the first location in a contiguos region is returned to you. Those locations remain allocated until you call free() on the address that was returned by malloc().
Notice that the Global data segment will get no bigger as a result of your program running. That is, it is not possible for you to "invent" a new global variable at run time. The heap, then, is located just after the Global data segment in the process and grows toward higher memory locations. If the heap and stack ever grow to cross each other, the proces is out of memory.
Notice also that because the heap is controlled only by calls to malloc() and free() (and not as a result of a change in scope), all heap variables are scoped global. Thus, a local variable can only be accessed in the scope it is defined because it will be deallocated when that scope terminates, but a heap variable can be accessed globally.
This all sounds straight forward but it can lead to confusion. For example, consider the code in mem2.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
void foo(int *foo_out)
{
*foo_out = 17;
return;
}
void bar(int *bar_out)
{
*bar_out = 18;
return;
}
void foobar(int *foobar_out)
{
int foo_val;
int bar_val;
foo(&foo_val);
bar(&bar_val);
*foobar_out = foo_val+bar_val;
return;
}
int main(int argc, char **argv)
{
int foobar_val;
foobar(&foobar_val);
printf("foobar_val: %d\n",foobar_val);
return(0);
}
This code is correct. The local variables in the function foobar() are
allocated on the stack before the call to foo() and remain there after
the call to bar(). They are then used fill in the integer pointer to
by the out pointer befire they are removed from the stack by the call to
return in foobar(). However, now look at mem3.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int *foo()
{
int foo_local;
foo_local = 17;
return(&foo_local);
}
int *bar()
{
int bar_local;
bar_local = 18;
return(&bar_local);
}
void foobar(int *foobar_out)
{
int* foo_ptr;
int *bar_ptr;
foo_ptr = foo();
bar_ptr = bar();
*foobar_out = *foo_ptr + *bar_ptr;
return;
}
int main(int argc, char **argv)
{
int foobar_val;
foobar(&foobar_val);
printf("foobar_val: %d\n",foobar_val);
return(0);
}
What's wrong with this code? It isn't the data types. The line
*foobar_out = *foo_ptr + *bar_ptr;is absolutely correct: foo_ptr and bar_ptr are correctly referenced as pointers to integers to get their values which is then stored in the location pointed to by the out parameter foobar_out.
The problem here is that both foo() and bar() return a pointer to memory that is in their respective stacks (that is, each returns a pointer to a local variable). When the return is executed, the pointer is return but the memory is deallocated. Thus the output is the sum of what ever "garbage" happened to be left on the stack after the return of bar().
Stare at this code for a minute before considering the code in mem4.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int *foo()
{
int *foo_local_ptr;
foo_local_ptr = (int *)malloc(sizeof(int));
*foo_local_ptr = 17;
return(foo_local_ptr);
}
int *bar()
{
int *bar_local_ptr;
bar_local_ptr = (int *)malloc(sizeof(int));
*bar_local_ptr = 18;
return(bar_local_ptr);
}
void foobar(int *foobar_out)
{
int* foo_ptr;
int *bar_ptr;
foo_ptr = foo();
bar_ptr = bar();
*foobar_out = *foo_ptr + *bar_ptr;
free(foo_ptr);
free(bar_ptr);
return;
}
int main(int argc, char **argv)
{
int foobar_val;
foobar(&foobar_val);
printf("foobar_val: %d\n",foobar_val);
return(0);
}
This code is correct even though it may look a little like the incorrect code
in mem3.c. Here foo() and bar() each
allocate memory on the heap (which is global), fill that memory in with an
integer value, and return the pointer value to that memory. The pointer
values are each stored in a local variable which is passed to the
return() call. Why is this okay when it wasn't okay in mem3.c?
In the previous example, the value that gets returned is the address of a variable on the stack (either foo's stack or bar's stack). In this last example, the pointer that is being returned came back from a call to malloc() which allocated the memory int he heap. Thus when foo() and bar() each return the memory is not deallocated from the heap hence the function foobar() can access it correctly.
Notice also that foobar() need to call free() or the memory will leak when foobar() returns. Why? Because there are no other variables in the program that hold the addresses that are necessary for free() to deallocate the memory once foobar() returns.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int foo(int a, int b, int c)
{
a = a + 10;
return(a+b+c);
}
int main(int argc, char **argv)
{
int foo_return;
foo_return = foo(100,101,102);
printf("foo_return: %d\n",foo_return);
return(0);
}
The function foo() adds 10 to its first parameter and then
returns the sum of the three parameters. This "works" but I suggest that it
is bad programming practice to modify parameters as if they were local
variables (since C's parameter passing mechanism is pass-by-value). Better
stylistically, is the code in mem6.c
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int foo(int a, int b, int c)
{
int local_a;
local_a = a + 10;
return(local_a+b+c);
}
int main(int argc, char **argv)
{
int foo_return;
foo_return = foo(100,101,102);
printf("foo_return: %d\n",foo_return);
return(0);
}
where foo() reads the value of a but does not modify it.
Finally (and mercifully) you can see the memory layout we have been discussing by running the code in mem7.c
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int A;
void foo(int *param_a)
{
int *local_p;
local_p = (int *)malloc(sizeof(int));
printf("address of local variable from main(): %p\n",
param_a);
printf("address of the first parameter in foo(): %p\n",
&(param_a));
printf("address of local variable in foo(): %p\n",
&local_p);
printf("address of variable on the heap: %p\n",local_p);
printf("address of global variable: %p\n",&A);
free(local_p);
return;
}
int main(int argc, char **argv)
{
int main_a;
foo(&main_a);
return(0);
}
Here it is on a Linux system:
./mem7 address of local variable from main(): 0x7fffcf90c3ec address of the first parameter in foo(): 0x7fffcf90c3a8 address of local variable in foo(): 0x7fffcf90c3b8 address of variable on the heap: 0x372702a0 address of global variable: 0x404020Curiously, here is the output from an old version of OSX
address of local variable from main(): 0x7fff50c1915c address of the first parameter in foo(): 0x7fff50c19138 address of local variable in foo(): 0x7fff50c19130 address of variable on the heap: 0x7ff043404af0 address of global variable: 0x10efe7028The heap is much closer (but still at a lower address) than the stack. Now for the weird part. Here is the output from a current version of OSX:
./mem7 address of local variable from main(): 0x16da4364c address of the first parameter in foo(): 0x16da43628 address of local variable in foo(): 0x16da43620 address of variable on the heap: 0x600001ef0030 address of global variable: 0x1023c4000The global variable is at a lower address but the heap looks like it is at a higher address. It really isn't. Take a look at mem8.c.
#include < unistd.h >
#include < stdlib.h >
#include < stdio.h >
int A;
int *global_p;
void foo(int *param_a)
{
int *local_p;
local_p = (int *)malloc(sizeof(int));
global_p = local_p;
printf("address of local variable from main(): %p\n",
param_a);
printf("address of the first parameter in foo(): %p\n",
¶m_a);
printf("address of local variable in foo(): %p\n",
&local_p);
printf("address of variable on the heap: %p\n",local_p);
printf("address of variable on the heap through global: %p\n",global_p);
printf("address of global variable: %p\n",&A);
if(local_p == global_p) {
printf("local_p and global_p are equal\n");
} else {
printf("local_p and global_p are not equal\n");
}
free(local_p);
return;
}
int main(int argc, char **argv)
{
int main_a;
foo(&main_a);
return(0);
}
Here is the output on Linux
address of local variable from main(): 0x7ffc704b6cec address of the first parameter in foo(): 0x7ffc704b6ca8 address of local variable in foo(): 0x7ffc704b6cb8 address of variable on the heap: 0x6a02a0 address of variable on the heap through global: 0x6a02a0 address of global variable: 0x404030 local_p and global_p are equalbut (strangely) here is the output on the current version of OSX:
./mem8 address of local variable from main(): 0x16b3a369c address of the first parameter in foo(): 0x16b3a3678 address of local variable in foo(): 0x16b3a3670 address of variable on the heap: 0x600001dbc030 address of variable on the heap through global: 0x600001dbc030 address of global variable: 0x104a64000 local_p and global_p are equalCool no?
What I think is happening here is that OSX is using a different memory layout (probably because of threads) that has the heap at a higher set of virtual addresses than the stack for main(). If you are interested in this kind of thing, try using the vmmap function on OSX with a running process. It looks like the default heap for malloc is something called "MALLOC_NANO" which sits are really high virtual addresses.
The point here is that the heap and the stack are in separate areas of memory. The heap is managed using malloc() and free() and the stack is automatically managed on function entry and exit. In this class, we will use the Linux (and not modern OSX) convention that the heap is at lower addresses than the stack.