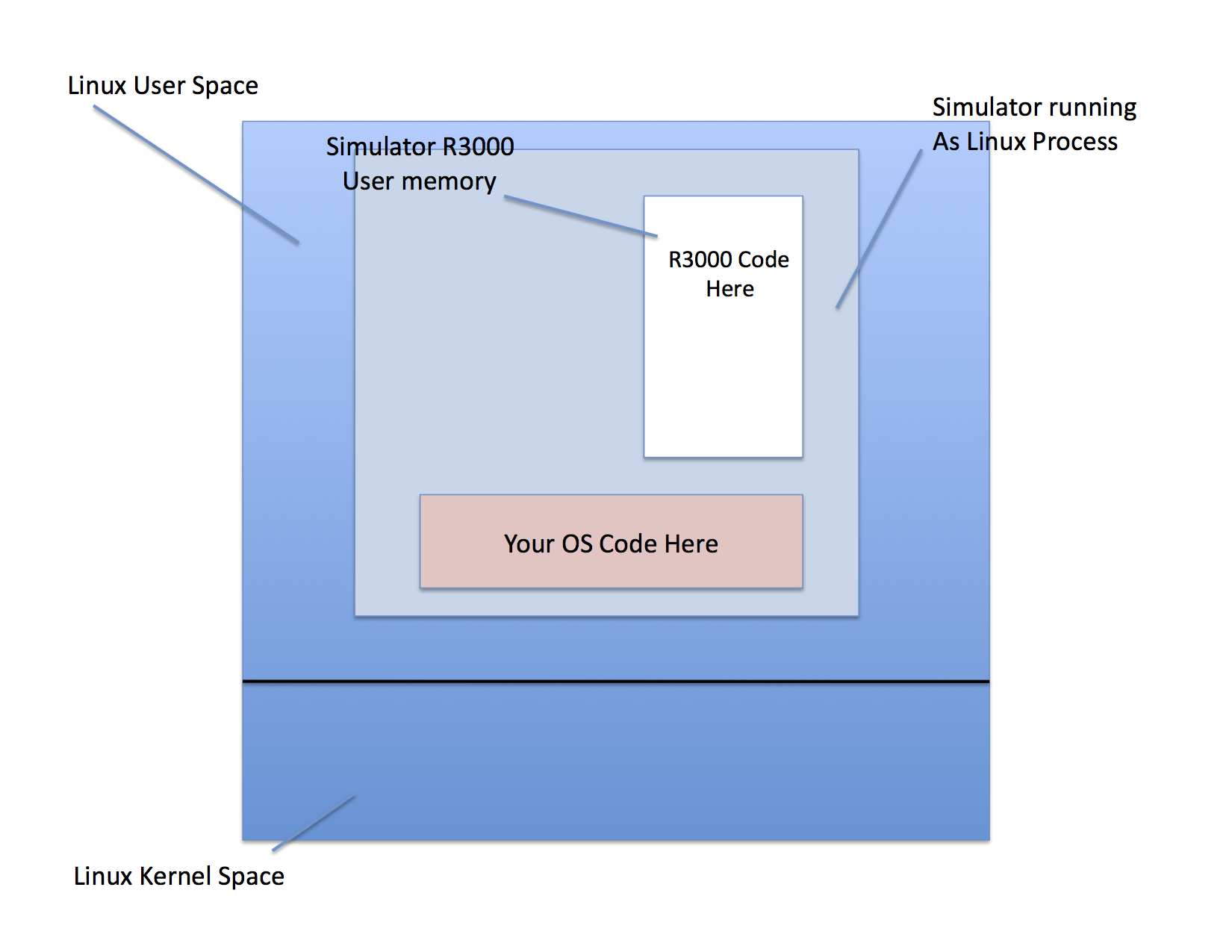
Thus, in this class, we will build an OS for a simulated machine. The advantage of doing this is that all of the development tools that are available for C programming will work, and also it is possible to use the native Linux system that runs the simulator to "stand in" for missing functionality at the beginning (like the file system).
Several questions usually arise regarding this approach.
In this way you can run the debugger on your OS. You can't run it on user-space programs that are running in user memory because they are compiled for the R3000. However, once you trap into the OS, you switch to x86 and the debugger will work. This is a HUGE advantage.
As the figure attempts to show, the simulator is running as a user process on a Linux system (in the CSIL). In that simulator process there is a memory space that has been allocated for user programs that run on your OS (which must be compiled for the R3000). You OS code gets compiled into the simulator so that when the simulator process runs, you can print out, debug, etc. as if it were just a normal Linux process. The only time it won't behave like a regular Linux process is if you try debug a program that is running in the simulated R3000 memory.
The switch between the R3000 memory and your OS code takes place when an interrupt (in the simulator) or an exception (generated by a program running in R3000 memory) takes place. There is a function in the simulator to return to R3000 space once the exception or interrupt is finished.
The first thing to understand is that the OS begins executing when exactly one of two things happens:
The next thing to understand is that the OS runs in privileged mode while user processes do not. Each CPU has a bit that says whether it is running in privileged mode or not (the x86 actually has two bits creating 4 modes, but only mode 0 is truly privileged). When the bit is set, the machine will execute any instruction in its instruction set and allow all memory to be accessed. When the privileged bit is clear, certain instructions defined by the machine's architecture and certain memory regions defined by the OS configuration cannot be accessed.
Thus when your program is running, the machine's privileged bit is clear. If it were not, you would be able to see the memory belonging to other programs, access the disk space belonging to other users, etc.
Put another way,
The process of transitioning from your program to the OS is called a protected transfer and it occurs when trap or interrupt occurs.
The CPU defines a set of trap codes that will be loaded into a special register or pushed on the stack when a trap occurs. Associated with each code is a jump address which the OS must initialize with the addresses of trusted functions that will be executed in privileged mode as a result of the trap. These addresses are usually pointers to functions that are loaded into a table called a jump table.

Each entry in the table must be initialized (during OS boot) with the address of a handler function that will be invoked when a trap occurs. The number of the trap serves logically as an index into the table. Thus when a trap happens, the OS has specified to the CPU what function it should call as an entry point with the privileged bit set.
This entry point must then contain code or calls to code that will be executed by the OS, in privileged mode, to handle the trap. If, for example, your program experiences a protection fault (say because you have tried to write through a zero pointer into the text segment of your process), the trap handler will cause your program to exit. It will tell the OS, essentially, to run the same code that you would run if you call exit() in your program which closes file descriptors, cleans up your memory state, etc.
When you make a system call, the compiler puts into the instruction list a special instruction that causes a trap that the OS will interpret as a request for OS functionality. Typically, the OS pushes a second code onto the stack right before it issues the OS trap. The OS trap handler, then, reads the value just above the stack pointer to know what system call has been issued. This code is used (like the trap code) to dispatch the system call to a system call handler.
Thus the logic for an OS system call is
In KOS, we will use a C-language switch{} statement to implement the system call table. You will need to write a system call handler for each system call you implement and add a case to the switch{} statement for each call. The R3000 simulator defines the system call codes it will use, and they are included in your OS code in a header file.
Thus, your code will include a switch{} statement that looks something like
switch (which) {
case SyscallException:
/* the numbers for system calls is in */
switch (type) {
case 0:
/* 0 is our halt system call number */
DEBUG('e', "Halt initiated by user program\n");
SYSHalt();
case SYS_exit:
/* this is the _exit() system call */
DEBUG('e', "_exit() system call\n");
printf("Program exited with value %d.\n", r5);
SYSHalt();
case SYS_write:
kt_fork(WriteCall,(void *)pcb);
DEBUG('e', "SYS_write system call\n");
break;
case SYS_read:
kt_fork(ReadCall,(void *)pcb);
DEBUG('e', "SYS_read system call\n");
break;
default:
DEBUG('e', "Unknown system call\n");
SYSHalt();
break;
}
Notice that it is a nested switch{}. The first case corresponds to the
type of trap that is being fielded. It is called an exception
in the KOS code base. I'll use the terms interchangeably. The second switch
is the dispatch table for the type of system call. In this code, five system
calls are implemented: halt(), exit(), write(), read(). In addition,
if the OS sees a system call come from a user process that it doesn't
recognizes, it will use the same system call entry point as the halt()
system call and cause the machine to halt.
switch (which) {
case ConsoleReadInt:
DEBUG('e', "ConsoleReadInt interrupt\n");
/*
* signal read thread that a character is ready */
V_kt_sem(Console_read_state.read_ready);
kt_joinall();
break;
case ConsoleWriteInt:
DEBUG('e', "ConsoleWriteInt interrupt\n");
V_kt_sem(Console_write_ready);
kt_joinall();
break;
default:
DEBUG('e', "Unknown interrupt\n");
kt_joinall();
break;
}
Again, we'll use C language switch{} statements to implement interrupt
dispatch (like we did for exceptions and system calls). In this code example,
there are two interrupts the OS is prepared to field: one from the console
write device (the terminal) and one from the console read device (the
keyboard).
/* * exception.c -- stub to handle user mode exceptions, including system calls * * Everything else core dumps. * * Copyright (c) 1992 The Regents of the University of California. All rights * reserved. See copyright.h for copyright notice and limitation of * liability and disclaimer of warranty provisions. */ #includeThus this is the entry point into the OS for traps that occur in the R3000 when a process is running in non-privileged mode. The simulator is running (logically) in privileged mode and it allows you to interrogate the state of the CPU (through the examine_registers() call) to determine what actions to take in the OS.#include "simulator.h" #include "scheduler.h" #include "kt.h" #include "syscall.h" #include "console_buf.h" void exceptionHandler(ExceptionType which) { int type = 0; int r5 = 0; /* * for system calls type is in r4, arg1 is in r5, arg2 is in r6, and * arg3 is in r7 put result in r2 and don't forget to increment the * pc before returning! */ switch (which) { case SyscallException: /* the numbers for system calls is in */ switch (type) { case 0: /* 0 is our halt system call number */ DEBUG('e', "Halt initiated by user program\n"); SYSHalt(); case SYS_exit: /* this is the _exit() system call */ DEBUG('e', "_exit() system call\n"); printf("Program exited with value %d.\n", r5); SYSHalt(); default: DEBUG('e', "Unknown system call\n"); SYSHalt(); break; } break; case PageFaultException: DEBUG('e', "Exception PageFaultException\n"); break; case BusErrorException: DEBUG('e', "Exception BusErrorException\n"); break; case AddressErrorException: DEBUG('e', "Exception AddressErrorException\n"); break; case OverflowException: DEBUG('e', "Exception OverflowException\n"); break; case IllegalInstrException: DEBUG('e', "Exception IllegalInstrException\n"); break; default: printf("Unexpected user mode exception %d %d\n", which, type); exit(1); } noop(); } void interruptHandler(IntType which) { switch (which) { case ConsoleReadInt: DEBUG('e', "ConsoleReadInt interrupt\n"); break; case ConsoleWriteInt: DEBUG('e', "ConsoleWriteInt interrupt\n"); break; default: DEBUG('e', "Unknown interrupt\n"); break; } noop(); }
The function examine_registers() is part of the R3000 bootstrap code. It runs in the kernel (privileged mode) and it copies the register values that were saved by the R3000 when the trap instruction was executed. In the lab, you will create a register save area in your PCB that is large enough to hold these saved registers so you can restore them before your kernel returns to user space. One quirk of the simulator, thoug, is that you can only call examine_registers() once per system call. That is, once a trap occurs and you call examine registers you cannot call it again.
Why?
Because examine_registers() uses the R3000 registers to make its copy and, as such, it affects the register contents. The first copy it makes is correct but in making that copy it changes the registers so the next copy will be incorrect with respect to what the user program was doing when it made the trap.
You will also need to arrange for the simulator to return to the proper place in the user program when the system call has finished. In my code, I have defined a function called SysCallReturn() that does two things:
int registers[NumTotalRegs]; . . . run_user_code(registers);If you load 0 into the PCReg and 4 into the NextPCReg registers, you'll start running the program from the beginning. Thus when you first launch a program you'll have code that looks like
int registers[NumTotalRegs];
for (i=0; i < NumTotalRegs; i++) {
registers[i] = 0;
}
registers[PCReg] = 0;
registers[NextPCReg] = 4;
.
.
.
run_user_code(registers);
which gives the new program zeros in all registers and launches it at the
beginning (after transitioning back to non-privileged mode). It may be
modularized differently, but that is essentially the logic. The
run_user_code() function will simply start running code in user space
with the register set you pass it.
memset(&main_memory,0,MemorySize);when executed in kernel space zeros out all of the memory in user space.
Kernel space memory is just the memory that your OS code is using. Because we are using a simulator, we can essentially allow your kernel to run in the same memory space as the simulator itself.
This duality of user space memory as a byte array and kernel space memory just being the memory of your OS can cause some confusion. For example, you can call malloc() in kernel space and it works just fine. If, however, you compile a code for the R3000 that calls malloc() and load it into user space and then run it, it will case a trap to occur and will attempt to make the sbrk system call (which is a system call malloc() uses to ask the kernel for more memory in the heap). Both are calls to malloc(). In one your kernel is making a request to what is logically a kernel memory allocator. The other is one that the R3000 program is trying to run and it needs your kernel's assistance via the sbrk system call to get memory allocated on the heap.
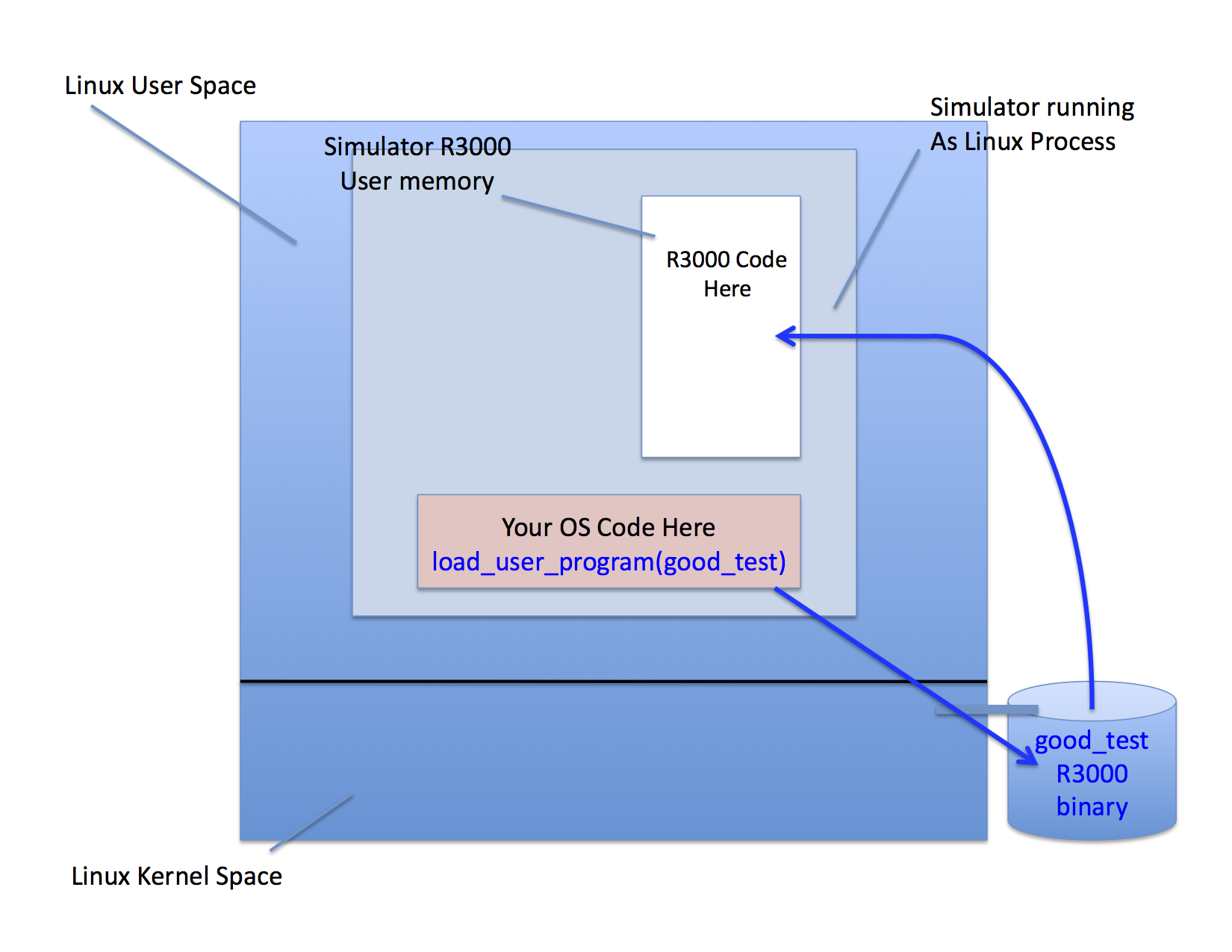
We have installed the necessary version of gcc on the CSIL machines and created a makefile that contains the correct compilation directives necessary to make an Ultrix binary for the R3000.
Take a look at http://www.cs.ucsb.edu/~rich/class/cs170/labs/kos_start_v2 and you will see a couple of C programs: good_test.c and evil_test.c. You can compile them simply by calling gcc on each and they will run.
However there is also a special makefile called Makefile.xcomp that will build the same programs using the cross compiler for Ultrix and the R3000. Try
make -f Makefile.xcompafter you copy these files in your own directory. You should see a file called good_test the same directory where you ran make. Try running it
./good_test -bash: ./good_test: Permission deniedThat's because Linux doesn't recognize it as an executable. Changing the permissions won't help. It is an R3000 binary for the DEC Ultrix OS -- Linux and x86 can't run it.
The following figure shows the path from the R3000 binary to main_memory:
The answer is that it allows your kernel to "remember" what it was doing on the stack if it has to block in the course of doing it.
For example, imagine that one of the assignments was to implement a file system and that you were implementing the read() system call. The disk system is several orders of magnitude slower than the CPU so while the disk is responding to a request to read a disk block, your OS must block the reading process. However, since it is a multi-process OS, while that process is blocked, your OS should be able to run other processes (it should not just sit and wait for that one process' read to complete).
In pseudocode, the call sequence in your OS might look like
exceptionHandler()
.
.
.
ReadSystemCall()
.
.
.
DiskBlockRead()
.
.
.
DiskDriverRead()
.
.
.
issue read command to disk
That is, in your OS, an exception occurs indicating that the process wants to
read some data. The exception handler recognizes the system call as a
call to read() and begins processing by calling the entry point for a
read() system call. This call will need to figure out what block you
need to read by consulting your file system data structures and then issue a
call to read a disk block. The DiskBlockRead() call will marshal up
some arguments and then call the disk driver to read a block at which point
your process must block.
But how can it block? You are running C code and these are C function calls. The call to DiskDriverRead() will queue the request for the disk driver and then it has nothing more to do. How does it wait? It can't in C -- it must return which causes it to return to the DiskBlockRead() call which returns to the ReadSystemCall() but this call can't return to the user process because the read hasn't completed yet. Each time you return you throw away any variables that were on the stack pertaining to this specific read.
What used to happen is that the OS would run some tricky code in the DiskBlockRead() code that would save off the registers that the kernel was using at that moment and also the values of variables that the kernel needed once the disk returns with the data block. Then, later, when the disk comes back with the data (which is announced by an interrupt) the kernel would search its records for a record that contains the register set and variable values. It would then reload them and continue the processing that would ultimately result in the process becoming unblocked.
In KOS, we use Kthreads to create these "blockable" calls. KOS has a stack switching mechanism built into it. When a thread sleeps or blocks on a semaphore, the registers and stack variables are automatically saved. When the thread begins running again, the values are restored and the thread continues where it left off. Thus, the KOS calling sequence would be
exceptionHandler()
.
.
.
kt_fork(ReadSystemCall,args-needed-for-read)
.
.
.
DiskBlockRead()
.
.
.
DiskDriverRead()
.
.
issue read command to disk
P_kt_sem(DiskSema);
kt_joinall();
schedule next process or noop waiting for interrupt
Then, when the disk is finished with its read, it throws an interrupt that
causes your code to gain control in interruptHandler(). The KOS
call sequence would be
interruptHandler() . . . DiskReadInt: V_kt_sem(DiskSema);at which point the previous call stack which had been blocked on DiskSema can continue knowing that the data is now available. It simply returns back through the call stack to the ReadSystemCall() function which finds the register set necessary to run the process, delivers the data to the process' buffer, and makes the process eligible to run again.
Thus, Kthreads makes it possible to implement multiple threads of control (each belonging to a separate process) in your kernel. They don't pre-empt each other but they do need to synchronize in order to handle asynchronous events (like in the disk read-disk interrupt example).
However, it may be that there are multiple processes that are attempting to read data from the disk. Since you don't know which process Kthreads will select when the V_kt_sem() is called, you can't simply let them queue up on DiskSema or you might return to a process whose read has not yet completed.
Instead, in this example, you'd need to use an additional semaphore so that only one thread at a time is waiting for the disk interrupt to come back and that thread is the one enabled. For example,
exceptionHandler()
.
.
.
kt_fork(ReadSystemCall,args-needed-for-read)
.
.
.
DiskBlockRead()
.
.
.
DiskDriverRead()
.
.
P_kt_sem(DiskRequestSema);
issue read command to disk
P_kt_sem(DiskSema);
.
.
.
V_kt_sem(DiskRequestSema);
return;
kt_joinall();
schedule next process or noop waiting for interrupt
Notice that the thread must first call P_kt_sem() on a semaphore that
allows it to issue a request to the disk. This semaphore,
DiskRequestSema, must be initialized to 1 so that the first
thread makes it in but others wait.
Then, after the interrupt occurs and the interrupt service routine calls V_kt_sem() on DiskSema, the thread that is waiting for the interrupt will wake up after its call to P_kt_sem() and continue executing. Eventually, it will need to return from the call to DiskDriverRead() and before it does, it should re-enable other threads to go ahead and make a disk request by calling V_kt_sem() on DiskRequestSema.
That is, the disk is used in a critical section.
What?
That's right. The disk can only be used one-at-a-time. That means at most one thread can be waiting for a pending disk interrupt. Which means that the waiting for a pending interrupt must be done in a critical section.
But what if the thread dies in the critical section or the disk fails or the interrupt gets lost?
Your system locks up and, perhaps, turns your screen a lovely shade of color.
That's precisely what you'd like to have happen. All of the state necessary to back out of the read system call processing is saved on the stack of the thread that is blocked on DiskSema. However your OS has now done all it can do for this process (which is blocked waiting for its read system call to complete) until the interrupt comes in indicating that the data is ready. Thus the OS has finished processing the trap for the time being and should move on to other business. When the interrupt occurs, the thread will be re-enabled and it can continue processing.
Thus, after the kt_joinall() the OS must decide what to do next given that the process which has made the system call must block. If there are other processes to run, the code shuld select one of them and switch to it (by calling run_user_process() on its saved set of registers). If there is no other process to run, the simulator includes a noop() instruction which parks the processor in a wait state waiting for an interrupt.
Thus you want to have the OS code switch back to the exceptionHandler() thread from wherever it happens to be when it runs out of work to do so it can complete the exception and find a new process to run or noop().
If this makes sense to you, then you realize that there must be a call to kt_joinall() in the interrupt handler as well.
interruptHandler()
.
.
.
DiskReadInt:
V_kt_sem(DiskSema);
kt_joinall()
reschedule the process that was interrupted or a new one or noop()
Why? Think about it for a bit and it should become clear. After an
interrupt, the OS should go back to what ever was happening. You can return
to the process that was running (if there was one running) or you can switch
to a new process (say because a time slice has expired) or you can
noop() if there is no process to run and wait for something to happen
like the arrival of another interrupt.
One last word about this example -- it is a stylized example. Do not use it verbatim to implement KOS since there are a bunch of details missing. For example, what happens if the disk read request is for more than one disk block? You wouldn't cause the read system call to return until all of the disk blocks have been read and that logic would need to be factored into how you synchronize with the disk.
Thus the intention here is for you to understand how Kthreads, KOS traps, system calls, and interrupts need to interact. The specific logic you need to implement different system calls will be unique to the system calls themselves.