The page table is a one-dimensional array of page table entries, indexed by page number, containing the following information: -------------------------------------------------------------------------- | Physical Frame # | valid | modified | referenced | protection | status | --------------------------------------------------------------------------The hardware specifies what the format of this entry is exactly so it will change from platform to platform, but a machine that supports full demand paging will contain these elements. Note also, that the figure is not drawn to scale. The valid, modified, and referenced fields are typically bit fields, and the protection field is typically two bits wide.
The protection field usually contains two bits that enable four kinds of access:
For what remains, recall that the page number is an index into a table of these entries from which the frame number is recovered.
------------------------------------------------- | swap device # | disk block # | swap file type | -------------------------------------------------Don't worry about the type. Just notice that what the kernel is doing here is storing the disk location where the backing store for a given page is located. Logically, these two entries are part of the sample table entry. they are typically implemented as separate tables, however, since the hardware will want pages tables to look a certain way, but backing store descriptors are completely up to the OS to define.
-------------------------------------------------- | ref count | swap device # | disk block # | PTE | --------------------------------------------------for each frame in the system. There are also some other fields that have to to with allocating and freeing frames, but we'll talk about those in a minute.
When the kernel allocates a frame to a page, it finds a free frame (somehow) and copies the swap device and disk block numbers into the frame table entry for that frame. Thus, the kernel always knows what block address is "backing" each frame in memory when the memory frame is allocated. When data is copied into a frame from backing store for a page, a pointer to the page table entry (PTE) for the page is put into the frame table entry for that frame. We'll see why this pointer is needed when we talk about freeing frames.
Before we move on, it is important to see how these data structures fit together. Here is the summary:
Doing a simple, linear search for a free frame is -- well -- simple and linear, but slow. You can speed the process up by picking a random point in the page table to start the search (and wrapping when you reach the end), or by remembering the last place you found a free page and starting from there, but these search algorithms all introduce search delay that can be avoided if a free list of frames is maintained. There is also an additional benefit to maintaining a free list (which you could also get with the linear search method) that we'll discuss.
First, though, the free list requires that the frame table entry have a next_free pointer.
-------------------------------------------------------------- | ref count | swap device # | disk block # | PTE | next free | --------------------------------------------------------------
Why FIFO order? Well, consider the following common scenario. A user of the system launches a commonly use program like vi (you all use vi I hope). The pages for vi fault into memory as described above, requiring frames (which are taken from the free list) and after a short while, the user exits the program. What happens to the frames that vi was using? They get put on the free list. Now another user launches vi. The straight forward thing to do is to fault the pages in again from scratch, but notice that if the frames haven't been reused by another program, the pages that are needed are probably still in memory, in frames that are on the free list. If we could find them on the free list, we wouldn't need to go all the way out to the disk and do a complete disk I/O to get them. That is, we could reclaim them. Finding a valid page on the free list and "unfreeing" is during a page fault is called a page reclaim.
Thus, we could search the free list from beginning to end looking for frames that are free, but contain the pages we need (from a previous program execution). If we searched linearly, it would be slow, but by putting frames at the tail of the list and getting free frames at the head of the list, frequently used frames migrate back toward the tail decreasing the chance that they will be chosen for over-write by another process.
To find a frame on the free list, we search for it by hashing the swap device number and the block number, and maintaining a hash table. That's right. This is exactly the same data structure that is used to manage the buffer cache in the file system. To implement the page cache, each frame table entry contains a next hash field as well.
-------------------------------------------------------------------------- | ref count | swap device # | disk block # | PTE | next free | next hash | --------------------------------------------------------------------------and the data structure looks like
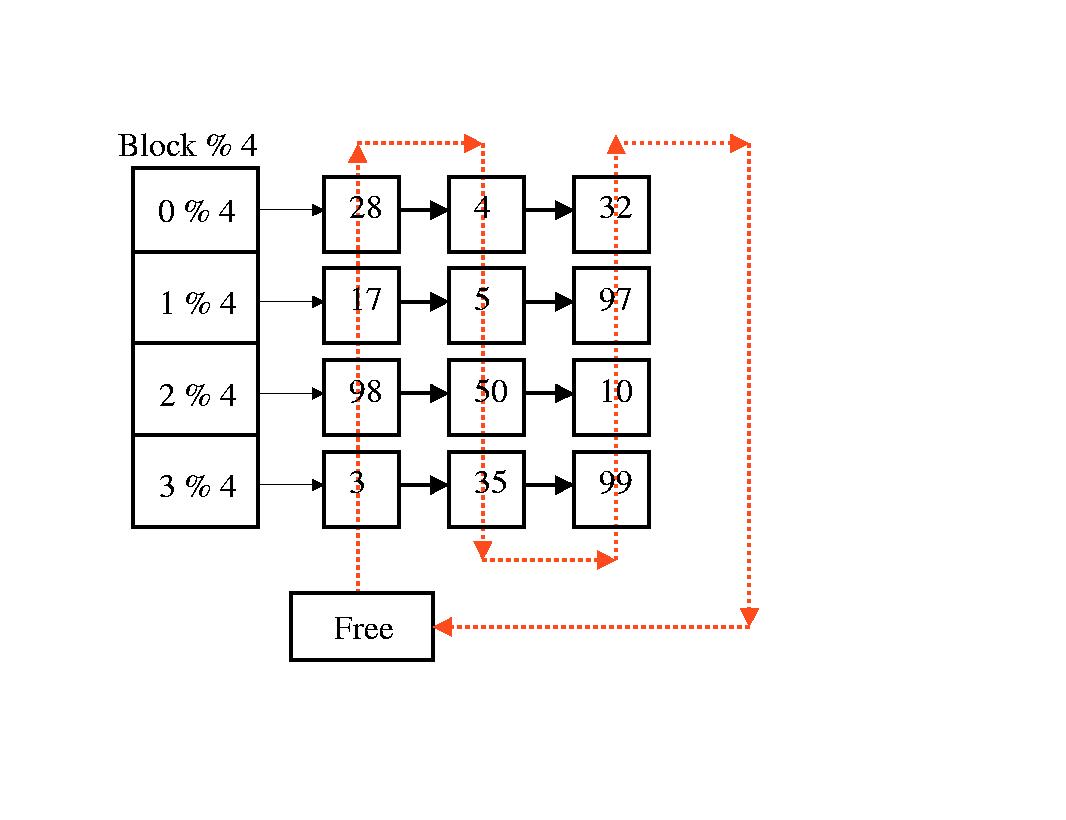 where the free list threads through the hash list. When a page fault
occurs, the page fault handler consults the disk block descriptor
entry for the swap device number and disk block number for the page. It
then hashes into the page cache to see if the frame is already in
memory (either because it is being shared by another process or because it is
on the free list). If the frame is there, and it is free (the reference
count is zero) it is taken off the free list and the page table
entry for the page is updated with the frame number. If it is not there,
then the page fault handler takes a free frame from the head of the
free list and schedules a disk read from the swap device for the copy of the
page that is on backing store.
where the free list threads through the hash list. When a page fault
occurs, the page fault handler consults the disk block descriptor
entry for the swap device number and disk block number for the page. It
then hashes into the page cache to see if the frame is already in
memory (either because it is being shared by another process or because it is
on the free list). If the frame is there, and it is free (the reference
count is zero) it is taken off the free list and the page table
entry for the page is updated with the frame number. If it is not there,
then the page fault handler takes a free frame from the head of the
free list and schedules a disk read from the swap device for the copy of the
page that is on backing store.
The term "dirty" is sometimes used to refer to a page that has been modified in memory, and the modified bit is occasionally termed "the dirty bit." Notice that a dirty page is always more current than the backing store copy. Thus, to "clean" a page, the copy that is in memory must be "flushed" back to backing store, updating the backing store copy to make it consistent with the memory copy.
Notice that there is a RACE CONDITION here to worry about. What happens if page fault handler finds a dirty, valid page on the free list and puts it on the queue for the page out thread (waking it up if need be), but because there are other frames ahead of it, the page doesn't get written to disk immediately. While the frame is waiting, the program that owns the frame wakes up and tries to access the frame? This condition can exist even in your lab. That bears repeating.
EVEN THOUGH YOUR KOS KERNEL USES KTHREADS, THIS RACE CONDITION WILL EXIST IN YOUR VIRTUAL MEMORY IMPLEMENTATION..
For those of you who believe kthreads obviates the need to think about race conditions, you have been warned.
But what to do? The answer is that the page table entry logically carries a status field indicating whether the page is in transition from memory to backing store. It is logically there because it may be located either in the page table entry or the block descriptor table entry, depending on the hardware. If the page fault handler finds the dirty, valid page in memory it checks the status field to determine of the page out thread is working on the page. If it is, typically, the page fault handler blocks itself by putting its process ID and the page table entry for the dirty page on a queue and going to sleep. The page fault handler thread sets the status field to indicate a page out is in progress when the frame is added to the page out thread's queue. When the page out thread finishes cleaning the page, it clears the modified bit and then checks the queue for any processes that are sleeping, waiting for a this page out to complete. If it finds any, it wakes them, and they proceed by reclaiming the page (now clean) from the free list. Simple no?
Notice that the valid and modified bits are in the page table for the page, but the free list is organized by frames. How does the kernel find the bits when it is examining a frame? It follows the pointer to the page table entry that gets put in the frame table entry when the frame is allocated. This "pointer" might actually be an index into the process table rather than a memory pointer if the page tables are paged (we won't discuss this nightmare further, but it is possible). Logically, though, it is a pointer.
One this to realize here is that if page sharing is taking place (i.e. the reference count is greater than 1) then multiple page table entries point to this frame table entry and all of them must be updates. The kernel can either search linearly through all of the page tables, in this case, or the PTE field in the frame table entry is really a pointer to a linked list of page table entries that have to be updated when the frame is deallocated.
What would happen if the OS, when confronted with no free frames, simply chose a frame that was being used by a program, cleared the valid in the program's page table entry and allocated the frame to the new program? If the program that originally owned the frame were using it, it would immediately take a page fault (as soon as it ran again) and the OS would steal another frame. It turns out that this condition occurs (in a slightly different form) and it is called thrashing. We'll discuss that in a minute, but the remarkable thing to notice here is that the OS can simply steal frames that are in use from other programs and those programs will continue to run (albeit more slowly since they are page faulting a great deal).
What actually happens has to do with locality of page references. It turns out that a large number of studies show that program access "sets" of pages for a good long while before they move on to other "sets." The set of pages that a program is bashing through repeatedly at any given time is called the programs run set. Very few programs have run sets that include all of the pages in the program. As a result, a program will fault in a run set and then stay within that set for a period of time before transitioning to another run set. Many studies have exposed this phenomenon and almost all VM systems exploit it. The idea, then, is to try and get the OS to steal frames from running programs that are no longer part of a run set. Since they aren't part of a run set the program from which the frames are stolen will not immediately fault them back in.
Here is the deal. First, every time a reference is made to a page (with read or write) the hardware sets the referenced bit in the page table entry. Every time.
The page stealer wakes up every now and then (we'll talk about when in a minute) and looks through all of the frames in the frame table. If the referenced bit is set, the page stealer assumes that the page has been referenced since the last time it was checked and, thus, is part of some processes run set. It clears the bit and moves on. If it comes across a page that has the referenced bit clear, the page stealer assumes that the has not been referenced recently, is not part of a run set, and is eligible to be stolen.
The actual stealing algorithms are widely varied as Unix designers seem to think that the way in which pages are stolen makes a tremendous performance difference. It might, but I've never heard of page stealing as being a critical performance issue. Still one methodology that gets discussed a great deal is called the clock algorithm. Again -- there are several variants. We'll just talk about the basics.
The page stealer then maintains two "hands" -- one "hand" points to the last place the page stealer looked in the frame table when it ran last. The other "hand" points to the last place it started from. When the page stealer runs, it sweeps through the frame table between where it started last and where it ended last to see if any of the referenced bits are set.
v = 0 or ref cnt = 0 : page is free so skip it v = 1, r = 1 : page is busy. clear and skip v = 1, r = 0, m = 0 : page is clean and unreferenced. steal v = 1, r = 0, m = 1 : page is dirty and unreferenced schedule cleaning and skip
Once the page stealer has run this algorithm for all of the pages between its start point and end point, it must move these points in the frame table. it does so by changing the new start point to be the old end point (wrapping around the end of the frame table if need be) and then it walks forward some specified number of frames (again wrapping if needed) clearing the referenced bit for each frame. These are the new start and end points ("hands") for the next time it wakes up.
It is called the clock algorithm because you can think of the frame table as being circular (due to the wrap around) and because start and end pointers work their way around the circle.
Variations on this theme include "aging counters" that determine run set membership and the way in which dirty pages are handled. I'll just briefly mention two such variations, but each Unix implementation seems to have its own.
If you think about it for a minute, you can convince yourself that the clock algorithm is an attempt to implement a Least Recently Used (LRU) policy as a way of taking advantage of spatial and temporal locality. The most straight-forward way to implement LRU, though, is to use a time stamp for each reference. The cost, of course, would be in hardware since a time stamp value would need to be written in the page table entry each time a reference occurred. Some systems, however, time stamp each page's examination by the page stealer using a counter. Every time the page stealer examines a page and find it is a "stealable" state, it bumps a counter and only steals the page after a specified number of examinations.
The other variation has to do with the treatment of dirty pages. SunOS versions 2.X and 3.X (Solaris is essentially SunOS version 4.X and higher) had two low-water marks: one for stealing clean pages and a "oh oh" mode when all stealable pages would be annexed. In the first mode, when the system ran a little short of pages, it would run the clock algorithm as described. If that didn't free enough pages, or if the free page count got really low, it would block the owners of dirty pages while they were being cleaned to try and get more usable on the free list before things got hot again. Usually, if the kernel found itself this short-handed, the system would thrash.
vmstat (after consulting the man page for details on its
function). Among other valuable pieces of information, it typically includes
paging rates. No Unix systems that I know of automatically throttle process
creations as a result of paging activity, but the information is typically
provided by a utility such as vmstat so that administrators can
determine when thrashing takes place.
In the disk block descriptor table contains both a swap device number and a disk block entry. The reason that both are included is that, on a very busy system, you might want to have multiple swap partitions so that parallel disk accesses are possible. Notice that in the way we have described the page out thread, there is only one queue to disk. If multiple swap partitions are configured, the kernel would maintain one disk queue per disk. Thus, the typical practice is to put multiple partitions (if they are desired) onto separate disks.
But I digress. For each swap partition (assume there is only one from here on out), the kernel must maintain a map of "free" and "busy" disk blocks. As a rule, swap space is cleared (or simply considered invalid) when the system boots so this map can be kept entirely in memory (there is no inconsistency problem like there is when in-core inodes have not been flushed to disk when a system halts unexpectedly).
Notice, though, that the swap partition must contain enough disk blocks to page all of the pages all running processes could ever have. Read this previous sentence carefully. Most people when asked the question "What is the advantage of virtual memory?" will respond with an answer that says a process' addressable memory can be larger than the physical memory of the machine. That is true, the system must have enough swap space to hold this larger memory -- for every simultaneously running process.
Before we talk about sizing further, however, we need to talk about swap space management. Older versions of Unix required that enough swap space be available to hold the entire address space of a newly-initiated process. To see why this policy would make sense, it helps to remember that machine memories were tens of megabytes and no kernel would permit a process to attempt a full 32 bit address space. The conservative approach, then, is to make sure there is enough swap before allowing a process to begin running. the other tenet in play here is that a running process should not be killed because a newly arrived process has suddenly run the machine out of swap space.
More modern systems take a different approach. To initiate a process, the kernel checks to see if fixed amount of initial swap is available. This space must be enough to cover the entire text and data segments, some part of the heap, and some part of the stack. Then, if during the running of the system, the kernel runs out of swap, it picks processes to terminate and kills them to free up their space. Usually big jobs are chosen (Linux uses this algorithm) but the goal is always to provide enough swap space to allow processes to page.
The more modern approach is to put a flag in the block descriptor table entry that indicates whether the page is on the swap device on in the original disk image. All pages start in the original image, but when they are modified (and become dirty) the current copy is written to swap.
Another point to be aware of has to do with whether swap space is contiguously allocated or not. The old thinking is that it should be since each run set is likely to be made up of contiguous pages. By keep pages together on the swap device, the theory goes, the disk head can possibly pre-fetch multiple pages on a page fault. Contiguous allocation, as you might now surmise on your own, implies the danger of fragmentation and these systems certainly could run out of swap when the swap space became too fragmented. The cost of not using contiguous space is potentially felt during a page fault, although if pre-fetching is not used, it is hard to understand what it might be.
As mentioned about in the discussion of the clock algorithm, the kernel maintains a count of free pages with the frame table and a low-water mark to indicate when page stealing should occur. A second method that the kernel uses to try and free up frames is to send to the swap device all of the frames associated with a given process, thereby putting them on the free list. Thus, the kernel maintains a swap out thread whose job it is to evict an entire job from memory, when there is a memory shortfall.
Again, your mileage may vary, but the basic idea is for the page stealer to try and do its work and, after making a complete sweep of memory, if there is still not enough free frames, for the page stealer to wake the swap out thread. The swap out thread chooses a job (based on the size of the job and how long it has run) and goes through its entire page table. It invalidates and frees any pages that have the valid bit set, but the modified bit clear, it schedules the valid and modified pages for disk write, and it sets the execution priority of the process to zero (or takes it off the run queue entirely) for a specified period of time. The idea is to pick a large, and old process (one that has received a lot of time already) and "park" it in swap space for a while. By doing so, and freeing all of its frames, the theory goes, a bunch of smaller jobs (which are probably interactive anyway) can get in and run. Also, the free frames might relieve paging pressure so that the unswapped jobs can complete, leaving more memory for the swapped job.
After a suitable interval (OS dependent, of course) the swapped job is put back in the run queue and allowed to fault its pages back in. Sometimes it is given extra time slices as well on the theory that it does not good to let it fault its pages in only to be selected again by the swap out thread for swapping.