Funded by
NSF RI
2007117.
This material is based upon work supported by the National
Science Foundation under Grant No. 2007117. Any opinions, findings, and
conclusions or recommendations expressed in this material are those of the
author(s) and do not necessarily reflect the views of the National Science
Foundation.
Project Summary
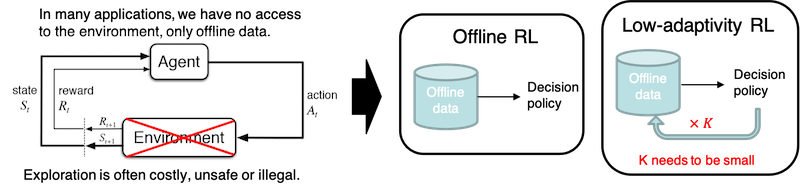
Reinforcement learning (RL) is one of the fastest-growing research areas in machine learning. RL-based techniques have led to several recent breakthroughs in artificial intelligence, such as beating human champions in the game of Go. The application of RL to real life problems, however, remains limited, even in areas where a large amount of data has already been collected. The crux of the problem is that most existing RL methods require an environment for the agent to interact with, but in real-life applications, it is rarely possible to have access to such an environment — deploying an algorithm that learns by trial-and-errors may have serious legal, ethical and safety issues. This project aims to address this conundrum by developing algorithms that learn from offline data. The outcome of the research could significantly reduce the overhead of using RL techniques in real-life sequential decision-making problems such as those in power transmission, personalized medicine, scientific discoveries, computer networking and public policy.
Talks
- Invited talk by Ming Yin at Yale University.
Institute for Foundations of Data Science
- Invited talk by Ming Yin at UC San Diego.
Information Theory and Applications (ITA), 2023.
- Invited talk by Ming Yin at Tsinghua University.
AI TIME 2023.
- Invited talk by Ming Yin at RIKEN.
The TrustML Young Scientist Seminar, 2023.
- Invited talk by PI Wang: "Advanced in Offline Reinforcement Learning and Beyond"
INFORMS Annual Meeting, 2022 [slides]
- Invited talk by PI Wang: "Towards Practical Reinforcement Learning: Offline RL and Low-Adaptive Exploration"
AI For Ukraine, UCSB CRML Summit 2022.
- Invited talk by Ming Yin at UCLA.
Big Data and Machine Learning Seminar
- Invited talk by PI Wang: "Uniform Offline Policy Evaluation and Offline Learning in Tabular RL"
Berkeley Simons Institute Workshop on RL from Batch Data and Simultation. [Slides]
- Invited talk by PI Wang: "Near Optimal Provable Uniform Convergence in OPE for Reinforcement Learning"
RL Theory Seminar [Slides, Video]
Research Results
- Offline Reinforcement Learning with Differential Privacy
Dan Qiao, Yu-Xiang Wang.
NeurIPS 2023. [arxiv]
- Posterior Sampling with Delayed Feedback for Reinforcement Learning with Linear Function Approximation
Nikki Lijing Kuang, Ming Yin, Mengdi Wang, Yu-Xiang Wang, Yi-An Ma
NeurIPS 2023. [preprint available soon]
- No-Regret Linear Bandits beyond Realizability
Chong Liu, Ming Yin, Yu-Xiang Wang.
UAI 2023. [arxiv]
- Offline Reinforcement Learning with Closed-Form Policy Improvement Operators
Jiachen Li, Edwin Zhang, Ming Yin, Qinxun Bai, Yu-Xiang Wang, William Yang Wang.
ICML 2023. [arxiv, code]
- Non-stationary Reinforcement Learning under General Function Approximation
Songtao Feng, Ming Yin, Ruiquan Huang, Yu-Xiang Wang, Jing Yang, Yingbin Liang
ICML 2023. [arxiv]
- Near-Optimal Differentially Private Reinforcement Learning
Dan Qiao, Yu-Xiang Wang.
AISTATS 2023 [arxiv]
- Offline Reinforcement Learning with Differentiable Function Approximation is Provably Efficient
Ming Yin, Mengdi Wang, Yu-Xiang Wang.
ICLR 2023. [arxiv]
- Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang.
Manuscript. [arxiv]
- Near-Optimal Deployment Efficiency in Reward-Free Reinforcement Learning with Linear Function Approximation
Dan Qiao, Yu-Xiang Wang.
ICLR 2023. [arxiv]
- Offline Reinforcement Learning with Differentiable Function Approximation is Provably Efficient
Ming Yin, Mengdi Wang, Yu-Xiang Wang.
ICLR 2023. [arxiv]
- Offline Reinforcement Learning with Differential Privacy
Dan Qiao, Yu-Xiang Wang.
NeurIPS 2023 [arxiv]
- Offline Stochastic Shortest Path: Learning, Evaluation and Towards Optimality
Ming Yin, Wenjing Chen, Mengdi Wang, Yu-Xiang Wang.
UAI 2022. [arxiv]
- Sample-Efficient Reinforcement Learning with loglog(T) Switching Cost
Dan Qiao, Ming Yin, Ming Min, Yu-Xiang Wang.
ICML 2022. [arxiv]
- Near-optimal Offline Reinforcement Learning with Linear Representation: Leveraging Variance Information with Pessimism
Ming Yin, Yaqi Duan, Mengdi Wang, Yu-Xiang Wang.
ICLR 2022. [openreview]
- Towards Instance-Optimal Offline Reinforcement Learning with Pessimism
Ming Yin, Yu-Xiang Wang.
NeurIPS 2021. [arxiv]
- Optimal Uniform OPE and Model-based Offline Reinforcement Learning in Time-Homogeneous, Reward-Free and Task-Agnostic Settings
Ming Yin, Yu-Xiang Wang.
NeurIPS 2021. [arxiv]
- Near-Optimal Offline Reinforcement Learning via Double Variance Reduction
Ming Yin, Yu Bai, Yu-Xiang Wang.
NeurIPS 2021. [arxiv]
-
Near Optimal Provable Uniform Convergence in Offlin Policy Evaluation for Reinforcement Learning
Ming Yin, Yu Bai, Yu-Xiang Wang.
AISTATS 2021. (*Plenary oral presentation) [arxiv]
-
Asymptotically Efficient Off-Policy Evaluation for Tabular Reinforcement Learning
Ming Yin, Yu-Xiang Wang.
AISTATS 2020. [arxiv]
- Towards Optimal Off-Policy Evaluation for Reinforcement Learning with Marginalized Importance Sampling
Tengyang Xie, Yifei Ma, Yu-Xiang Wang.
NeurIPS 2019. [arxiv]
- Provably Efficient Q-Learning with Low Switching Cost
Yu Bai, Tengyang Xie, Nan Jiang, Yu-Xiang Wang.
NeurIPS 2019. [arxiv]
Education
- CS292F Statistical Foundation of Reinforcement Learning
Instructor: Yu-Xiang Wang, 2021 Spring [ Course website ]
- Mini-Symposium on Statistical RL
Nine teams of student presentations. [ Website ]
- Undergraduate Research Project: "Empirical Benchmarking of Offline RL methods"
Ari Polakof, Noah Pang, Qiru Hu, Sara Mandic. Advised by Ming Yin and Yu-Xiang Wang.
[ Project webpage]