
|
CS177: Project 6 - Linear Cryptanalysis (20% of project score)Project GoalsThe goals of this project are:
Administrative InformationThe project is an individual project. It is due on Wednesday, June 14, 2023, 23:59:59 PST (no deadline extensions; late flags will not be accepted). IntroductionLinear cryptanalysis is a known-plaintext attack that was introduced by Matsui in 1993. An early target of this attack was the Data Encryption Standard (DES), but linear cryptanalysis turned out to be a powerful technique that worked against numerous other block ciphers as well. In response, most new block ciphers, including many of the candidates submitted for the Advanced Encryption Standard (AES) process were designed using techniques specifically targeted at thwarting linear cryptanalysis. This included the eventual winner and new AES standard, the Rijndael cipher. Detailed DescriptionThe goal in this challenge is to leverage linear cryptanalysis to break a simple substitution-permutation network (SPN) cipher and recover the encryption key. The input to our block cipher are 16-bit plaintext blocks. The SPN takes each block and combines it with the 48-bit secret key, producing 16-bit ciphertext blocks as output. A SPN takes a block of the plaintext and the key as inputs, and applies several alternating rounds of substitution boxes (S-boxes) and permutations to produce a ciphertext block. Substitution and permutation are two fundamental cryptographic operations that work together to create confusion and diffusion, so an attacker cannot figure out the key, even if they have access to both the unencrypted and encrypted versions of the message (this is called a plaintext-ciphertext pair), or many such pairs.
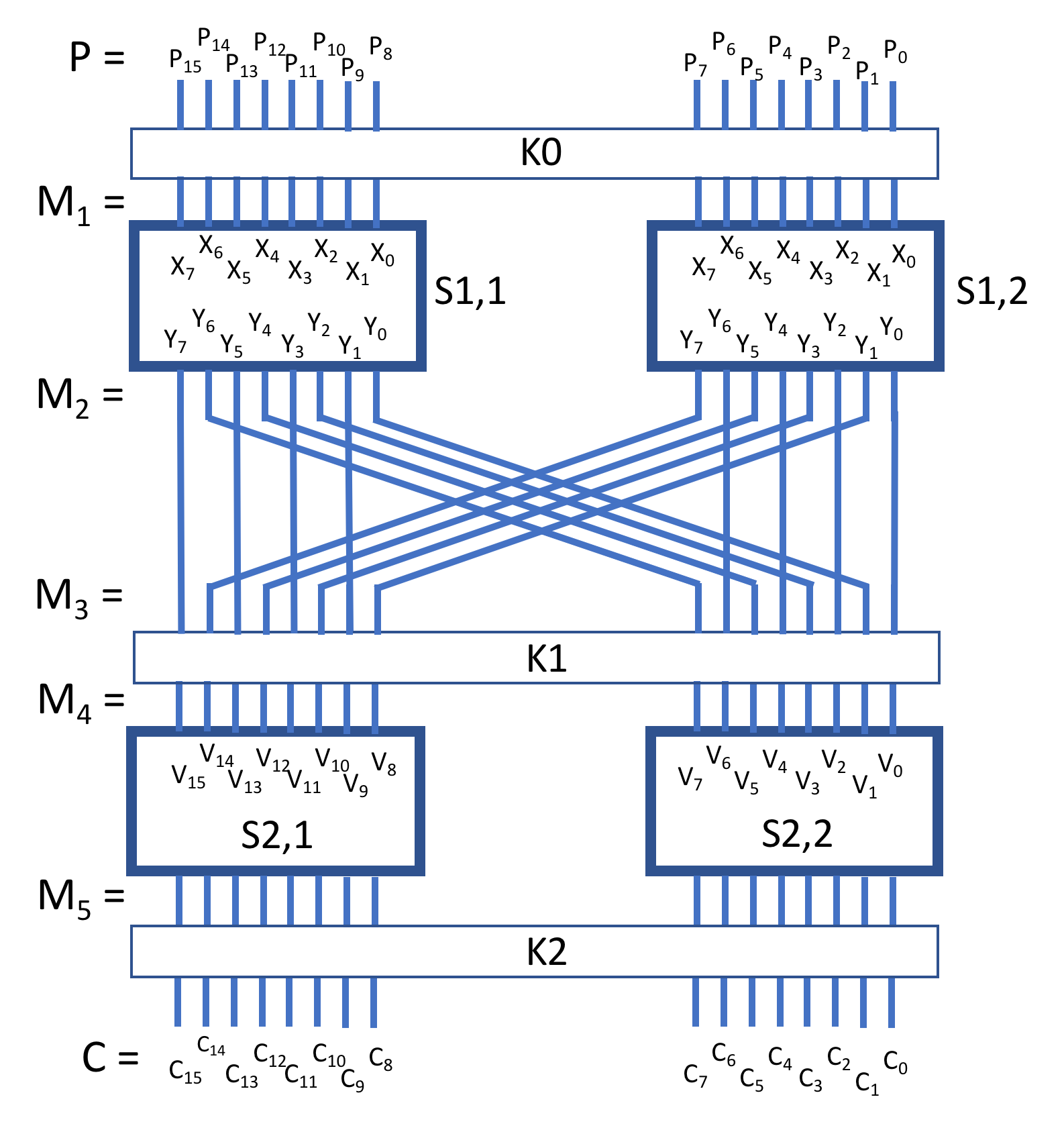
The diagram here shows an overview of our simple cipher, which has only two "rounds." We have a 48 bit master key K that is split into three 16 bit keys, K0, K1 and K2. Each plaintext message (P), which is input into the cipher, is 16 bits. Our cipher performs the following six steps.
You are given 512 pairs of plaintext and corresponding ciphertext. The ciphertext was created by encrypting the plaintext with your secret key. Once you have downloaded the plaintext/ciphertext pairs and used cryptanalysis to recover the key, you will submit the key to us and receive a flag. This flag should then be submitted as in previous assignments. We have written a simple server that you can connect to and interact with via netcat (or a similar tool). Basically, use netcat (nc) to connect to the port that is given to you when you spin up your instances via CTFd. There, you will find a simple text-based menu that allows you to perform three operations:
HintsIf you have not done much cryptanalysis in the past, breaking a 48-bit key with a "reasonable" (but extremely simple) block cipher might seem like a daunting task. In addition to reviewing the lecture material, I also recommend this tutorial on linear cryptanalysis. You are given a large set of plaintexts that were encrypted by the SPN and the resulting ciphertexts. These were all encrypted using the same key. With a great SPN, like AES, having these pairs wouldn't help you recover the key, but with the SPN in this homework these pairs give you everything you need to know to break it. By analyzing this many pairs you can identify a relationship between the plaintexts and their ciphertexts that will allow you to reconstruct the key. The goal of an SPN is to hide linear relationships between the plaintext and ciphertext, by performing many rounds of substitutions and permutations. The linear relationships most people are familiar often look like y = ax + b. A linear equation can have any number of unknown variables, what makes it linear is that each variable is only multiplied by a constant (rather than by other variables or itself). For instance x + y + z = 0 is also a linear equation. Here, if we find enough equations that relate x, y and z, we could determine their values. In the same vein, if we have enough linear equations that have bits of the key as our unknown variables, we can determine the key. But in our case the linear relationships look slightly different. It's an exclusive-or (XOR ⊕) of individual bits. XOR is equivalent to addition in modulo 2, and of course addition is linear.
0 ⊕ 0 = 0 ➝ 0 + 0 = 0 mod 2
0 ⊕ 1 = 1 ➝ 0 + 1 = 1 mod 2
1 ⊕ 1 = 0 ➝ 1 + 1 = 0 mod 2
If you can identify enough XOR equations between bits in the plaintext, bits in the ciphertext, and bits in the key (your unknown variable) you can solve for the key. For example, one such relationship could be that we know if you XOR the first bit in the plaintext with the first key bit and XOR that with the fourth bit in its ciphertext the result equals 1.
P1 ⊕ K1 ⊕ C4 = 1
However, an SPN wants to prevent equations like this, and to do so it uses the substitution box (S-box). Such substitutions are essentially nonlinear operations with the goal to prevent linear relationships (like the equation above) from occurring with high probability. With a perfect S-Box, any possible XOR expression relating your bits in a plaintext, ciphertext and key would equal 1 exactly 50% of the time and 0 50% of the time. This gives us no information. But, if our S-Box is imperfect enough, we can construct linear equations that are true for significantly more than 50% of the time, and then we can use those to guess the key. For example, let's say our equation above is only true 75% of the time.
P1 ⊕ K1 ⊕ C4 = 1, for 75% of plaintexts
This is a linear approximation. If we can determine enough of these relationships, we can use the approximations to recover the key. But in order to find equations relating the plaintext, ciphertext and key, we first need to find the same type of linear approximations relating the inputs and outputs of the S-Box. For example, an approximation might be a relationship where if you XOR the 1st, 4th and 5th bit of an S-Box input (X) with the 2nd and 6th bit of the output (Y) from the S-Box, it equals 1, 60% of the time.
X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 = 1, 60% of the time
Because each input has 8 bits, there are 2^8 = 256 different combinations of those input bits. The same is true for the output. So if each has 2^8 different combinations of their bits, then there are 2^8 * 2^8 = 2^16 possible expressions like the one in the example above. For example, X0 ⊕ Y0 is a possible expression, X1 ⊕ Y1 ⊕ Y2 is another, etc. Given our 2^16 possible expressions, we now evaluate each one on every possible input (of which there are 2^8). By collecting this data, you can see if some of these expressions equals either 1 or 0 significantly more than 50% of the time. If, say, X2 ⊕ Y3 = 1 for 85 out of 100 inputs, that would mean this linear equation has a strong bias of 35% (it's 35% more likely than 50%) and could help you recover the key. If X2 ⊕ Y3 = 1 for only 15 out of 100 inputs then it would have an equally strong but negative bias (-35%). What matters is the absolute value of the bias. Now you build a linear approximation table for the input and output bits of the S-box. Each entry will represent the number of times that the linear relationship between the corresponding input and output bits is 0 (or 1), for all possible 256 input values to the S-box. For a perfect cipher, we would expect that such a linear relationship holds exactly half of the time (2^8 / 2 = 128). If you find entries that are much larger or much smaller than this number, it means that there is a large bias, and you probably want to use this linear relationship for your subsequent analysis. These equations can be expressed in terms of masking the input and the output. For instance, with X as the input and Y as the output of the S-Box, take our previous example:
X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 = 1
The input mask would be the byte 00110010b in binary (50 in decimal), where the bits 1, 4 and 5 are set. The output mask would be 01000100b (68 in decimal). When a bitwise AND is done between the input and output and their respective mask, the only bits that will be left will be X1, X4, X5, and Y2, Y6. If these bits were 1 in the input/output, they will remain 1, otherwise they will remain 0. All other bits become 0.
X' = X & 00110010b
Y' = Y & 01000100b
After applying these masks you can then find the value of X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 by counting the number of 1 bits in X' and adding that to the number of 1 bits in Y' and then checking if the resulting number is even or odd, meaning X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 = 0 or X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 = 1, respectively. Luckily for you, our S-box is weak, and you'll be able to identify useful relationships. Even luckier, there is an additional weakness in our SPN: it only has two rounds. This is an advantage because with a good SPN, multiple rounds of the permutation step means that these linear relationships are diluted. This attack would still work on an SPN with more than 2 rounds if it still had a weak S-Box, but the attack becomes slightly more involved. That attack would rely on what's called the Piling Up Lemma, which is explained in the tutorial linked above. But in our case due to the small number of rounds, you can directly use the linear relationship(s) with the strongest bias from the previous step to determine relationships between the plaintext, ciphertext and key. Some SPNs, including AES, use one key and expand it into multiple keys using a "key expansion" algorithm. This is done so a modified key (which is still based on the original key) is used per round. In that kind of system, if you find one of these keys, you can find the original key by reversing the key expansion algorithm. In our case, we instead have three different keys, one before each S-box, and one after the last S-box. Thankfully this is only a minor inconvenience, but you'll have to recover each key sequentially. First, you have to guess the last key value, which is K2. And you will have to check whether your guess is correct. For this, you will use the biases you found together with all the plaintext/ciphertext pairs. There are 2^16 possible values for K2, and you will iterate over each possible value. For each possible value for K2 (let's call such a guess k), you will iterate over every plaintext/ciphertext pair (P and C). Specifically, for each pair, you will reverse Step 6 of our cipher (by XOR'ing k with the ciphertext C. Then, you'll use the inverse S-Box to reverse Step 5 (for each of the top and bottom halves). At this point, you'll have the values at Step 4, M4' and M4''. We call these values V' and V'' in our diagram, where V' is the top half, bits V15...V8 and V'' is the bottom half, bits V7...V0. Remember, these are only the correct V' and V'' values if k is correct (that is, if k = K2). (The bitshift and binary-and in the equations below are to get the top and bottom half of the message, respectively.)
V' = inverseS-Box[ (k ⊕ C) >> 0xFF ] -> (bits k15...k8 are each XOR'd with bits C15...C8)
V'' = inverseS-Box[ (k ⊕ C) & 0xFF ] -> (bits k7...k0 are each XOR'd with bits C7...C0)
Now, you'll use our linear approximations to relate the bits of the plaintext P to the bits V15...V0. Remembering what our cipher looks like, we know the input to the first S-Box are the halves of P ⊕ K0, where K0 is our first key. The outputs are then shuffled and XOR'd with K1, resulting in V' and V'', or when combined, V. We don't know K1, so we cannot directly undo the XOR in Step 4, but XOR is a linear bitwise operation, meaning that the permutation in Step 3 can still be undone by reversing the permutation, which is easy to do. At this point, you only need to care about one of the S-Box operations in Step 2 (it doesn't matter which one). Let's look at the input X and output Y of an S-box (in the first round) in terms of P and V, which we know, and K0 and K1, which we don't know.
X = P ⊕ K0
Y = V ⊕ K1 (and taking into account the permutation layer)
This is where having many plaintext/ciphertext pairs becomes useful. Even though we don't know the exact X and Y for our S-Box, we can approximate them with P and V, knowing that for each plaintext/ciphertext pair, P and V are modified by the same K0 and K1. Due to the weakness of our S-Box, the linear relationship with the highest probability, or bias, that you found should suffice for our purposes. Let's assume that after computing the biases, the linear relationship most likely to be true is our earlier example:
X1 ⊕ X4 ⊕ X5 ⊕ Y2 ⊕ Y6 = 1 for 60% of S-Box inputs (10% bias)
We can substitute the bits from X and Y with bits from P, V, K0, K1 (again, keeping in mind the permutation layer):
P1 ⊕ K0,1 ⊕ P4 ⊕ K0,4 ⊕ P5 ⊕ K0,5 ⊕ V2 ⊕ K1,2 ⊕ V6 ⊕ K1,6 = 1
We don't know the bits in K0 and K1, but we know they will be the same every time. So, if we check every every plaintext/ciphertext pair, this equation will either equal 0 or 1 with a similar likelihood as the original bias. That is
P1 ⊕ P4 ⊕ P5 ⊕ V2 ⊕ V6 = 0 for ~60% of S-Box inputs (-10% bias)
or
P1 ⊕ P4 ⊕ P5 ⊕ V2 ⊕ V6 = 1 for ~60% of S-Box inputs (+10% bias)
So, let's zoom out. You're checking all possibilities, k, for the last key K2. For each k, you take your most likely linear relationship and apply it to each plaintext/ciphertext pair, P and C. When tested on all the pairs, you find the probability that this equation equals 1, and compute the bias, which is the difference between this probability and 50%. If the absolute value of this bias is similar to the absolute value of the bias of the original linear approximation, then that key guess, k, is your K2. Once you have K2, you can basically "strip off" one round of the cipher. That is, you can repeat the process described above and iterate over all possible key values for (parts of) K1, and all the plaintext and ciphertext pairs that you have. This allows you to determine K1 . With K1 and K2, it is easy to get K0 with a single pair of plaintext and ciphertext. Just run the ciphertext backwards until (and before) you reach the last key (K0), then compute a simple XOR between this value and the plaintext. CreditsMany thanks to Perri Adams (@perribus) for the detailed cryptanalysis write-up. |
{kind=link}